<!-- .slide: id="intro" data-transition="concave" -->
# Cloud Native Meetups
[github.com/govcloud](https://github.com/govcloud) <i class="fa fa-download"></i></li>
Note:
This is a presentation created in conjunction with the Canadian Digital Services and Cloud Operations team at Statistics Canada.
---
<!-- .slide: id="agenda" data-transition="concave" -->
# Agenda
* Planning Items
* Containers
* Kubernetes
* CNCF
* Azure AKS and ACS
* Workflows
Note:
The agenda for today is fairly straightforward though I would like to apologize in advance for any minor foibles as this is our first meeting and honestly we are just trying to get off the ground.
I thought just before everything else I would mention why I feel a group like this should exist.
* This is going to be a long road not everything can be done cloud natively immediately
* Stand on shoulders of giants
* We have some amazing resources in GoC
* Strive for developer freedom
* Change government culture
* Skunkworks
* Go afficionados?
* Worried about how we get sold things in Government: Azure Service Fabric, Pivotal, and OpenShift, there are standards we should use them
We are going to try to keep the planning items discussion capped at an hour and a bit in order to ensure enough time to demo some of the initial work being done at Statistics Canada.
---
<!-- .slide: id="planning" data-transition="concave" -->
# Planning Items
* Scope
* Methods of communication
* Virtual meetups
* Subsequent presentations
* Miscellaneous
Note:
## Scope
1) How would we like to define Cloud Native and our Scope?
* We should ignore standard IAAS custom cloud type functionality
* We need to facilitate hybrid cloud (AWS, Azure, OpenStack, On Premise, etc)
* We need to follow Canada's Open First Whitepaper (this prevents alot of implicit issues)
* We use the CNCF code of conduct are we fine with that for now?
* Use govcloud repo and hugo static site for blogs
* Will be hosting cloud native youtube videos shortly
* Host our own containers / container registry?
Cloud native computing uses an open source software stack to be:
a) Containerized. Each part (applications, processes, etc) is packaged in its own container. This facilitates reproducibility, transparency, and resource isolation.
b) Dynamically orchestrated. Containers are actively scheduled and managed to optimize resource utilization.
c) Microservices oriented. Applications are segmented into microservices. This significantly increases the overall agility and maintainability of applications.
2) Do we have any preferences over the methods of communication?
I personally would like to have a Slack Channel but i'm pretty sure this one might be opionated. Ideally we need a place where can just communicate and ask questions to each other throughout day.
3) Are we okay with some meetups occurring completely virtually?
I am a very big proponent of this and feels this type of flexibility will allow us to try to have a public meetup at least once a month.
4) Who would like to present at subsequent meetings?
I know there is tons of amazing work done out there by you fine GoC folks, lets us see!
5) Are there any other agenda items that were missed?
Already so we still have "x" amount of minutes left before need to start the presentation.
This part was purposely left open to gather input for relevant things we may have missed.
* Vendor participation
* Evangelism
* Fostering GoC community
* Social events after meetings
---
<!-- .slide: id="containers" data-transition="concave" -->
# Containers
> Containers will yield the following benefits to Government:
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Platform independence</li>
<li>Resource efficiency and density</li>
<li>Effective isolation and resource sharing</li>
<li>Speed</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Immense and smooth scaling</li>
<li>Operational simplicity</li>
<li>Developer productivity</li>
<li>Development pipeline</li>
</ul>
</div>
Note:
Everyone that learns about containers and their server immutability concept invariably loves them, because of the power they give, both on the development and in the deployment sides.
**Platform independence: Build it once, run it anywhere**
A major benefit of containers is their portability. In particular containers help to facilitate a cloud native approach via a microservices architectural design pattern.
A container wraps up an application with everything it needs to run, like configuration files and dependencies. This enables you to easily and reliably run applications on different environments such as your local desktop, physical servers virtual servers, testing, staging, production environments and public or private clouds.
This portability grants organisations a great amount of flexibility, speeds up the development process and makes it easier to switch to another cloud environment or provider, if need be.
**Resource efficiency and density**
Since containers do not require a separate operating system, they use up less resources. While a VM often measures several gigabytes in size, a container usually measures only a few dozen megabytes, making it possible to run many more containers than VMs on a single server.
Since containers have a higher utilisation level with regard to the underlying hardware, you require less hardware, resulting in a reduction of bare metal costs as well as datacentre costs.
**Effective isolation and resource sharing**
Although containers run on the same server and use the same resources, they do not interact with each other. If one application crashes, other containers with the same application will keep running flawlessly and won’t experience any technical problems. This isolation also decreases security risks: If one application should be hacked or breached by malware, any resulting negative effects won’t spread to the other running containers.
**Speed: Start, create, replicate or destroy containers in seconds**
As mentioned before, containers are lightweight and start in less than a second since they do not require an operating system boot. Creating, replicating or destroying containers is also just a matter of seconds, thus greatly speeding up the development process, the time to market and the operational speed. Releasing new software or versions has never been so easy and quick. But the increased speed also offers great opportunities for improving customer experience, since it enables organisations and developers to act quickly, for example when it comes to fixing bugs or adding new features.
**Immense and smooth scaling**
A major benefit of containers is that they offer the possibility of horizontal scaling, meaning you add more identical containers within a cluster to scale out. With smart scaling, where you only run the containers needed in real time, you can reduce your resource costs drastically and accelerate your return on investment. Container technology and horizontal scaling has been used by major vendors like Google and Twitter for years now.
**Operational simplicity**
Contrary to traditional virtualisation, where each VM has its own OS, containers execute application processes in isolation from the underlying host OS. This means that your host OS doesn’t need specific software to run applications, which makes it simpler to manage your host system and quickly apply updates and security patches.
**Improved developer productivity and development pipeline**
A container-based infrastructure offers many advantages, promoting an effective development pipeline. Let’s start with one of the most well-known benefits. As mentioned before, containers ensure that applications run and work as designed locally. This elimination of environmental inconsistencies makes testing and debugging less complicated and less time-consuming since there are fewer differences between running your application on your workstation, test server or in production environment. The same goes for updating your applications: you simply modify the configuration file, create new containers and destroy the old ones, a process which can be executed in seconds. In addition to these well-known benefits, container tools like Docker offer many other advantages. One of these is version control, making it possible for you to roll-out or roll-back with zero downtime. The possibility to use a remote repository is also a major benefit when working in a project-team, since it enables you to share your container with others.
## Data Points
* 71% of Fortune 100 companies are running containers
___
<!-- .slide: id="docker" data-transition="concave" -->
# Docker
* Docker for Windows / Mac
* Docker Intricacies
* Composer w/PHP
* Data Science (SAS, Kylo, NiFi)
Note:
___
<!-- .slide: id="docker" data-transition="concave" -->
# Container Design Patterns
* There are certain fundamental truths
* Patterns developed from KISS, DRY, SoC
* Inspired from 12 factors app
> Facilitate creating a containerized application that can be automated and orchestrated effectively by a cloud-native platform.
Note:
The principles for creating containerized applications listed below use the container image as the
basic primitive and the container orchestration platform as the target container runtime environment.
Following these principles will ensure that the resulting containers behave like a good cloudnative
citizen in most container orchestration engines, allowing them to be scheduled, scaled, and
monitored in an automated fashion. These principles are presented in no particular order.
___
<!-- .slide: id="k8s-principles-single-concern" data-transition="concave" -->
# Single Concern

Note:
The SCP principle dictates that every container should address a single concern and do it well.
Achieving it is easier than achieving SRP in the object-oriented world, as containers usually manage
a single process, and most of the time that single process addresses a single concern.
If your containerized microservice needs to address multiple concerns, it can use patterns such
as sidecar and init-containers to combine multiple containers into a single deployment unit (pod),
where each container still handles a single concern. Similarly, you can swap containers that address
the same concern. For example, replace the web server container, or a queue implementation container,
with a newer and more scalable one.
___
<!-- .slide: id="k8s-principles-image-immutability" data-transition="concave" -->
# Image Immutability
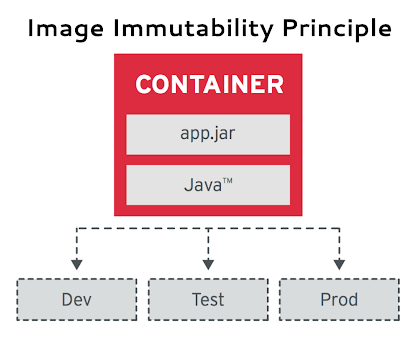
Note:
Containerized applications are meant to be immutable, and once built are not expected to change
between different environments. This implies the use of an external means of storing the runtime
data and relying on externalized configurations that vary across environments, rather than creating
or modifying containers per environment. Any change in the containerized application should
result in building a new container image and reusing it across all environments. The same principle
is also popular under the name of immutable server/infrastructure and used for server/host management,
too.
Following the IIP principle should prevent the creation of similar container images for different environments,
but stick to one container image configured for each environment. This principle allows
practices such as automatic roll-back and roll-forward during application updates, which is an important
aspect of cloud-native automation.
___
<!-- .slide: id="k8s-principles-high-observability" data-transition="concave" -->
# High Observability
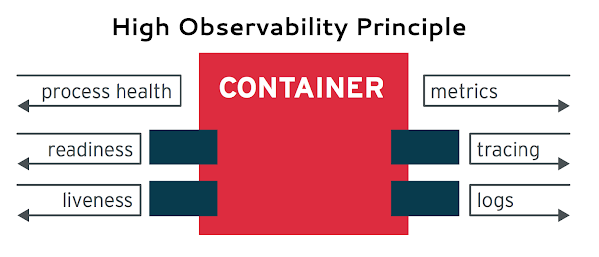
Note:
Containers provide a unified way for packaging and running applications by treating them like a
black box. But any container aiming to become a cloud-native citizen must provide application programming
interfaces (APIs) for the runtime environment to observe the container health and act
accordingly. This is a fundamental prerequisite for automating container updates and life cycles in a
unified way, which in turn improves the system’s resilience and user experience.
In practical terms, at a very minimum, your containerized application must provide APIs for the
different kinds of health checks—liveness and readiness. Even better-behaving applications must
provide other means to observe the state of the containerized application. The application should
log important events into the standard error (STDERR) and standard output (STDOUT) for log aggregation
by tools such as Fluentd and Logstash and integrate with tracing and metrics-gathering libraries
such as OpenTracing, Prometheus, and others.
Treat your application as a black box, but implement all necessary APIs to help the platform observe
and manage your application in the best way possible.
___
<!-- .slide: id="k8s-principles-lifecycle-conformance" data-transition="concave" -->
# Lifecycle Conformance

Note:
The HOP dictates that your container provide APIs for the platform to read from. The LCP dictates
that your application have a way to read the events coming from the platform. Moreover, apart from
getting events, the container should conform and react to those events. This is where the name of
the principle comes from. It is almost like having “write API” in your application to interact with
the platform.
There are all kind of events coming from the managing platform that are intended to help you
manage the life cycle of your container. It is up to your application to decide which events to handle
and whether to react to those events or not.
But some events are more important than others. For example, any application that requires a
clean shutdown process needs to catch signal: terminate (SIGTERM) messages and shut down as
quickly as possible. This is to avoid the forceful shutdown through a signal: kill (SIGKILL) that follows
a SIGTERM.
There are also other events, such as PostStart and PreStop, that might be significant to your application
life-cycle management. For example, some applications need to warm up before service
requests and some need to release resources before shutting down cleanly.
___
<!-- .slide: id="k8s-principles-process-dispoability" data-transition="concave" -->
# Process Disposability

Note:
One of the primary motivations for moving to containerized applications is that containers need to
be as ephemeral as possible and ready to be replaced by another container instance at any point in
time. There are many reasons to replace a container, such as failing a health check, scaling down
the application, migrating the containers to a different host, platform resource starvation, or
another issue.
This means that containerized applications must keep their state externalized or distributed and
redundant. It also means the application should be quick in starting up and shutting down, and even
be ready for a sudden, complete hardware failure.
Another helpful practice in implementing this principle is to create small containers. Containers in
cloud-native environments may be automatically scheduled and started on different hosts. Having
smaller containers leads to quicker start-up times because before being restarted, containers need
to be physically copied to the host system.
___
<!-- .slide: id="k8s-principles-self-containment" data-transition="concave" -->
# Self Containment
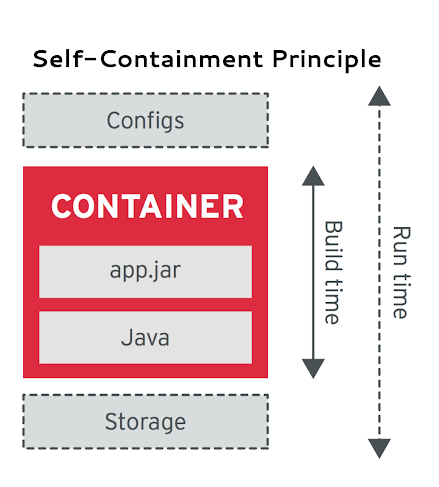
Note:
This principle dictates that a container should contain everything it needs at build time. The container
should rely only on the presence of the Linux® kernel and have any additional libraries added
into it at the time the container is built. In addition to the libraries, it should also contain things such
as the language runtime, the application platform if required, and other dependencies needed to run
the containerized application.
The only exceptions are things such as configurations, which vary between different environments
and must be provided at runtime; for example, through Kubernetes ConfigMap.
Some applications are composed of multiple containerized components. For example, a containerized
web application may also require a database container. This principle does not suggest merging
both containers. Instead, it suggests that the database container contain everything needed to run
the database, and the web application container contain everything needed to run the web application,
such as the web server. At runtime, the web application container will depend on and access the
database container as needed.
___
<!-- .slide: id="k8s-principles-runtime-confinement" data-transition="concave" -->
# Runtime Confinement
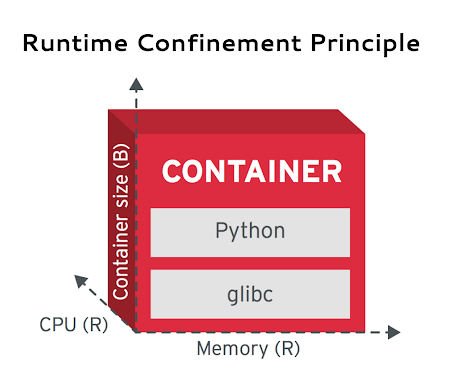
Note:
S-CP looks at the containers from a build-time perspective and the resulting binary with its content.
But a container is not just a single-dimensional black box of one size on the disk. Containers have
multiple dimensions at runtime, such as memory usage dimension, CPU usage dimension, and other
resource consumption dimensions.
This RCP principle suggests that every container declare its resource requirements and pass that
information to the platform. It should share the resource profile of a container in terms of CPU,
memory, networking, disk influence on how the platform performs scheduling, auto-scaling, capacity
management, and the general service-level agreements (SLAs) of the container.
In addition to passing the resource requirements of the container, it is also important that the application
stay confined to the indicated resource requirements. If the application stays confined, the
platform is less likely to consider it for termination and migration when resource starvation occurs.
___
<!-- .slide: id="k8s-structural-patterns" data-transition="concave" -->
# Structural Patterns
* Sidecar
* Initializer
* Ambassador
* Adapter
Note:
The patterns in this category are focused on the structure and relationships among
containers in a pod to satisfy the different use cases.
One way to think about container images and containers is similar to classes and
objects in the object oriented world. Container images are the blueprint from which
containers are instantiated. But these containers do not run in isolation, they run
in other abstractions such as pods and namespaces that provide unique runtime
capabilities. The forces that affect containers in pod give birth to patterns such as:
* Sidecar describes how to extend and enhance the functionality of a preexisting container without changing it.
* Initializer describes init containers feature that allows separation of concerns by providing a separate lifecycle for initialization related tasks and the main application.
* Ambassador pattern provide a unified interface for accessing services outside of the pod.
* Adapter takes an heterogeneous system and makes it conform to a consistent unified interface that can be consumed by the outside world easier.
___
<!-- .slide: id="k8s-structural-patterns-sidecar" data-transition="concave" -->
# Sidecar
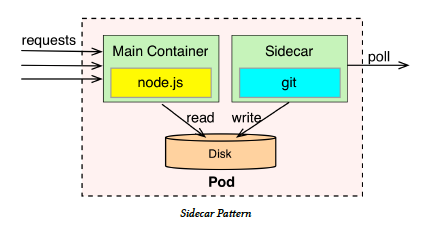
Note:
A sidecar container extends and enhances the functionality of a preexisting container
without changing it. This is one of the fundamental container patterns that allows
single purpose build containers to cooperate closely together for a greater outcome.
This simple pattern allows runtime collaboration of containers, and at the same
time enables separation of concerns for both containers, which might be owned
by separate teams using different programing languages, having different release
cycles, etc. It also promotes replaceability and reuse of containers as node.js and git
synchronizer can be reused in other applications and different configuration either
as a single container in a pod, or again in collaboration with other containers.
___
<!-- .slide: id="k8s-structural-patterns-initializer" data-transition="concave" -->
# Initializers
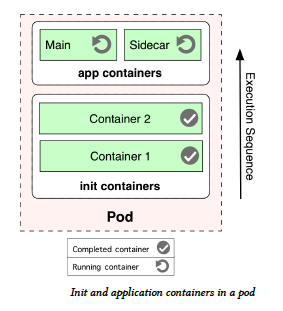
Note:
Kubernetes init containers feature allows separation of concerns by providing a
separate lifecycle for initialization related tasks and the main application.
Init containers in Kubernetes are part of the pod definition, and they separate all
containers in a pod in two groups: init containers and application containers. All
init containers are executed in a sequence, one by one, and all of them have to
terminate successfully before the application containers are started up. In that sense,
init containers are like constructor instructions in a Java class which help for the
object initialization. Application containers on the other hand run in parallel, and
there is guarantee on the order in which they will start up.
And last but not least, init containers enable separation of concerns and allow
keeping containers single purposed. An application container can be created by the
application engineer and focus on the application logic only. An init container, can
be authored by a deployment engineer and focus on configuration and initialization
tasks only.
___
<!-- .slide: id="k8s-structural-patterns-ambassador" data-transition="concave" -->
# Ambassador
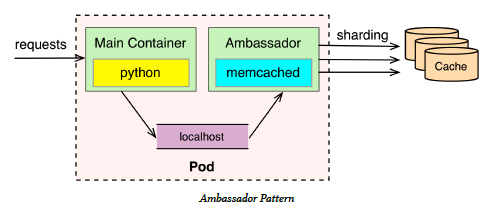
Note:
The Ambassador is a specialized Sidecar that it is responsible for hiding the complexity
and providing a unified interface for accessing services outside of the pod.
To demonstrate the pattern, the very first example that comes into mind is using a
cache for an application. Accessing a local cache on the development environment
may be a simple configuration, but on the production environment we may need
a client configuration the is able to connect to the different shards of the cache.
Another example would be consuming a service that requires lookup in a registry
and to service discovery on the client side. A third example would be consuming a
service over a non-reliable protocol such as HTTP where to protect our application
we have to use circuit breaker logic, configure time outs, perform retries, etc.
In all of these of cases, we can use an Ambassador container that hides the complexity
of accessing the external services and provides a simplified view and access to the
main application container over localhost.
The benefits of this pattern are similar to those of Sidecar pattern where it allows
keeping containers single purposed and reusable. With such a pattern, our application
container can focus on its business logic and delegate the responsibility and specifics
of consuming the external service to another specialized container. This also allows
us the creation of specialized and reusable Ambassador containers that can be
combined with other application containers.
___
<!-- .slide: id="k8s-structural-patterns-adaptor" data-transition="concave" -->
# Adaptor
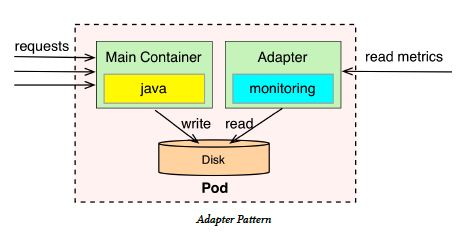
Note:
This pattern takes an heterogeneous system and makes it conform to a consistent
unified interface with standardise and normalized format that can be consumed by
the outside world.
With this approach, every service represented by a pod, in addition to the main application
container would have another container that knows how to read the custom
application specific metrics and expose them in a generic format understandable by
the monitoring tool. We could have an adapter container tha knows how to export
Java based metrics over HTTP, another adapter container in a different pod that
exposes Python based metrics over HTTP, etc. For the monitoring tool, all metrics
would be available over HTTP, and in a common normalized format.
Another example would be logging. Different containers may log information in
different format and level of details. An Adapter can normalize that, clean it up,
enrich with some contextual information using SelfAwareness pattern and then make
it available for scraping by the centralized log aggregator.
___
<!-- .slide: id="k8s-design-patterns" data-transition="concave" -->
# Network Tips
* Cluster IP
* Node Port
* Load Balancer
* Ingress
Note:
___
<!-- .slide: id="k8s-design-patterns-clusterip" data-transition="concave" -->
# Cluster IP
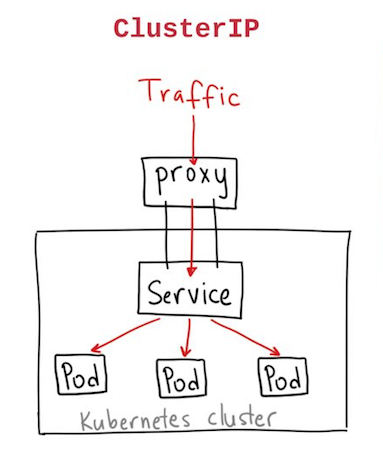
Note:
ClusterIP: Exposes the service on a cluster-internal IP.
Choosing this value makes the service only reachable from within the cluster.
This is the default ServiceType
___
<!-- .slide: id="k8s-design-patterns-nodeport" data-transition="concave" -->
# Node Port
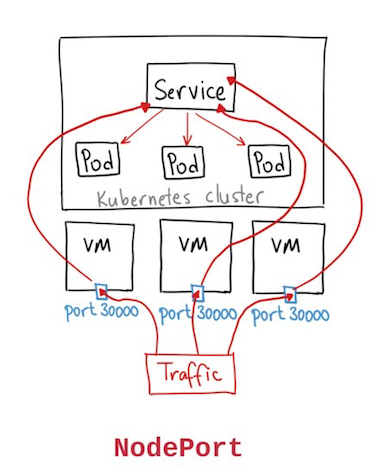
Note:
A NodePort service is the most primitive way to get external traffic directly to your service. NodePort, as the name implies, opens a specific port on all the Nodes (the VMs), and any traffic that is sent to this port is forwarded to the service.
___
<!-- .slide: id="k8s-design-patterns-loadbalacner" data-transition="concave" -->
# Load Balancer
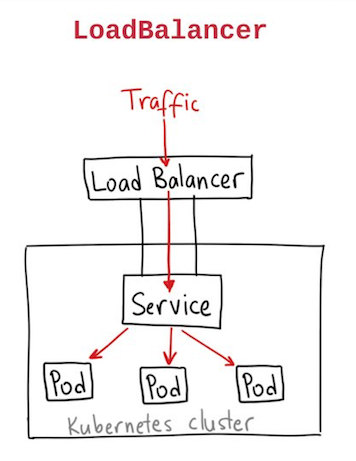
Note:
A LoadBalancer service is the standard way to expose a service to the internet. On GKE, this will spin up a Network Load Balancer that will give you a single IP address that will forward all traffic to your service.
___
<!-- .slide: id="k8s-design-patterns-ingress" data-transition="concave" -->
# Ingress
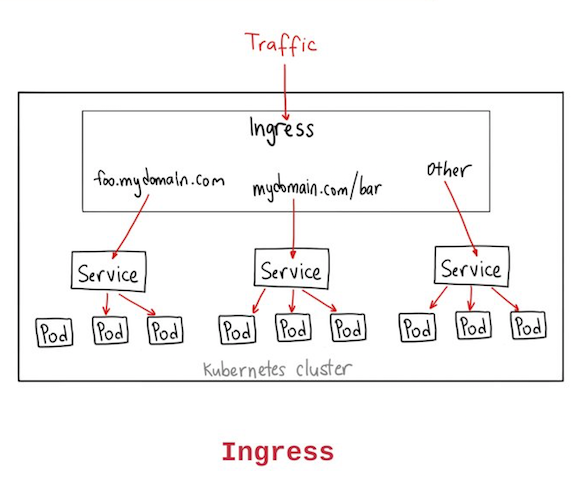
Note:
Unlike all the above examples, Ingress is actually NOT a type of service. Instead, it sits in front of multiple services and act as a “smart router” or entrypoint into your cluster.
You can do a lot of different things with an Ingress, and there are many types of Ingress controllers that have different capabilities.
The default GKE ingress controller will spin up a HTTP(S) Load Balancer for you. This will let you do both path based and subdomain based routing to backend services. For example, you can send everything on foo.yourdomain.com to the foo service, and everything under the yourdomain.com/bar/ path to the bar service.
Ingress is probably the most powerful way to expose your services, but can also be the most complicated. There are many types of Ingress controllers, from the Google Cloud Load Balancer, Nginx, Contour, Istio, and more. There are also plugins for Ingress controllers, like the cert-manager, that can automatically provision SSL certificates for your services.
Ingress is the most useful if you want to expose multiple services under the same IP address, and these services all use the same L7 protocol (typically HTTP). You only pay for one load balancer if you are using the native GCP integration, and because Ingress is “smart” you can get a lot of features out of the box (like SSL, Auth, Routing, etc)
---
<!-- .slide: id="k8s" data-transition="concave" -->
# Kubernetes
> Kubernetes will yield the following benefits to Government:
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Managed complexity</li>
<li>Vendor lock-in</li>
<li>Multi cloud</li>
<li>Self-healing</li>
<li>Open Service Broker</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Google backed</li>
<li>Vibrant community</li>
<li>Big name supporters</li>
<li>Flexibility</li>
</ul>
</div>
Note:
As containers become more popular each day, more technology is being developed to help unleash all the power containers can offer. One of the most useful technologies created around containers in the deployment side is orchestrators.
A container orchestrator is a software that is able to orchestrate and organize containers across any number of physical or virtual nodes. The potential of this is enormous, as it greatly simplifies the deployment of the infrastructure (each node only has Docker installed) and its operation (as all servers are exactly equal). The container orchestrator takes in account things as failing nodes, adding more nodes to the cluster or removing nodes from the cluster by moving the containers from one node to another to keep them available at all times.
While containers + orchestrators technology not only resolves a lot of problems related with infrastructure management, it also resolves a lot of problems regarding deploying software in the infrastructure, as the software, its dependencies and runtime are always deployed at the same time, minimizing the errors commonly associated to deployments in non-immutable environments.
Kubernetes has won the orchestrator wars, hands down and as of 2018 now takes center stage. This is proved by every single cloud vendor integrating with it and providing their own managed service. Additionally by most PAAS's offering first class support for it. (Pivotal, OpenShift, Tectonic, ...)
**Managed complexity**: Automation of the deployment, scaling, and operation of application containers in a clustered environment via primitives
**Vendor Lock-in**: Essentially every major cloud provider (public, private, hybrid) support Kubernetes
**Multi-Cloud**: Ideal for managing multi-cloud environments / workloads
**Self-healing**: Auto-placement, auto-restart, auto-replication, auto-scaling
**Google Backed**: Originally built by Google leveraging a decade of experience running containers at scale
**Vibrant Community**: One of the fastest moving projects in open source history, 2nd largest. Additionally over 30,000 users on slack many google engineers.
**Big Name Supporters**: Google, Microsoft, AWS, IBM, RedHat, Oracle, VMWare, Intel, Pivotal etc
**Flexibility**: Simplicity of a PaaS with the flexibility of IaaS
> Interesting data points
* 54% of Fortune 100 companies are running Kubernetes
* Housed within a large, neutral open source foundation, the Cloud Native Computing Foundation
* CNCF consists of enterprise companies such as Microsoft, Google, AWS, SAP, Oracle, Pivotal, etc
* Kubernetes has won the orchestration wars and is recognized as the de facto standard for container orchestration
* Gartner: By 2020, more than 50% of global enterprises will be running containerized applications in production.
* With that, Kubernetes has emerged as the leading orchestration method in the market with a 71% adoption rate.
___
<!-- .slide: id="k8s-primitives" data-transition="concave" -->
# Powerful Primitives
> Containers will yield the following benefits to Government:
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Pod</li>
<li>Service</li>
<li>Volume</li>
<li>Namespace</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>ReplicaSet</li>
<li>Deployment</li>
<li>StatefulSet</li>
<li>DaemonSet</li>
<li>Job</li>
</ul>
</div>
Note:
___
<!-- .slide: id="k8s-tips" data-transition="concave" -->
# Helpful Tips
* Interact with the community
* kubectl autocomplete
* Illustrated Guide to Kubernetes
* Container Fundamentals Refresher Video
Note:
Illustrated Guide to K8S: https://www.youtube.com/watch?v=4ht22ReBjno
Containers: https://www.youtube.com/watch?v=EnJ7qX9fkcU
---
<!-- .slide: id="k8s-dev" data-transition="concave" -->
# Development Toolset
> The dev tooling on top of k8s namely Helm, Draft, Brigade and Kashti are the Bell Labs of the cloud era
Note:
This was a quote that I have heard more then a few times by some big name developers working on AKS @ Microsoft.
I'll only be demonstrating the Helm component but wanted to very quickly highlight applicable tooling.
___
<!-- .slide: id="k8s-draft" data-transition="concave" -->
# Draft
> Draft is a tool that makes it easy to build apps that run on Kubernetes.
* Generates Packs detected from app language
* Packs are simply a Dockerfile and Helm Chart
* Draft comes with support for 8 language packs
Note:
___
<!-- .slide: id="k8s-charts" data-transition="concave" -->
# Helm
> Helm is a tool for managing Kubernetes charts. Charts are packages of pre-configured Kubernetes resources.
* Kubernetes package manager
* Reproducible builds of your k8s applications
* Intelligently manage your k8s manifest files
* Manage releases of Helm packages
* Subcharts
Note:
Helm makes doing reliable reproducible deployments easy to Kubernetes, and is the standard way of working with Kubernetes.
Think of Helm as the package manager for Kubernetes similar to apt/yum/apk. If you deploy applications to Kubernetes, Helm makes it incredibly easy to version those deployments, package it, make a release of it, and deploy, delete, upgrade and even rollback those deployments as charts. Charts being the terminology that helm use for package of configured Kubernetes resources.
Actually run through some Helm examples:
* Traefik
* Kylo
* NiFi
* OpenFaaS
Helm + VSTS:
http://jessicadeen.com/tech/microsoft/how-to-deploy-to-kubernetes-using-helm-and-vsts/
___
<!-- .slide: id="k8s-monocular" data-transition="concave" -->
# Monocular
* Web based UI for managing K8S apps
* Add custom secured Chart repositories
* Active Directory / OAUTH support
* Indexes and scans charts periodically
Note:
Monocular is a part of the Helm project and aims to provide a way to search for and discover apps that have been packaged in Helm Charts. Monocular includes a scanning back-end for indexing charts and their metadata and a simple user interface.
---
<!-- .slide: id="vscode" data-transition="concave" -->
# VSCODE
> A Visual Studio Code extension for interacting with Kubernetes clusters.
Integrates with:
* kubectl
* docker
* git
* helm
* draft
Note:
A Visual Studio Code extension for interacting with Kubernetes clusters. This extension combines the vs-kubernetes extension by @brendandburns and the vs-helm extension by @technosophos.
---
<!-- .slide: id="cncf" data-transition="concave" -->
# CNCF
* Kubernetes (Graduated)
* Prometheus (+ Grafana)
* Envoy (Istio)
* Rook
Note:
The Linux Foundation is the parent of CNCF.
___
<!-- .slide: id="cncf-prometheus" data-transition="concave" -->
# Prometheus (+ Grafana)
* Proactive monitoring
* Cluster visibility and capacity planning
* Trigger alerts and notification(s)
* Metrics dashboards
Note:
___
<!-- .slide: id="cncf-prometheus-helm" data-transition="concave" -->
# Prometheus (+ Grafana)
```sh
helm install --name grafana -f values govcloud/grafana
helm install --name grafana -f values govcloud/prometheus
```
Alternatively:
[coreos/prometheus-operator](https://github.com/coreos/prometheus-operator) <i class="fa fa-github"></i></li>
Note:
---
<!-- .slide: id="azure-aks" data-transition="concave" -->
# AKS
* Managed Kubernetes environment
* No charge for control plane
* Auto Upgrades
* Quick and efficient scaling
Note:
The easiest way to manage and operate your Kubernetes environments.
This service features an Azure hosted control plane, automated upgrades, self-healing, easy scaling and a simple UX for both developers and cluster operators.
You will never be billed for the management infrastructure which includes the K8S control plane.
Additionally AKS itself is free and you will only pay for the Nodes (VMs) that are added.
___
<!-- .slide: id="aks-create" data-transition="concave" -->
# AKS Cluster Creation
```sh
az group create --name k8s-gov \
--resource-group k8s-gov \
--location canadaeast \
--node-count 1
--node-vm-size Standard_D4s_v3 \
--kubernetes-version 1.9.5 \
--tag k8s-gov
```
Note:
___
<!-- .slide: id="aks-context" data-transition="concave" -->
# AKS Cluster Context
```sh
az aks get-credentials --resource-group k8s-gov \
--name=k8s-gov
```
Note:
___
<!-- .slide: id="aks-browse" data-transition="concave" -->
# AKS Cluster Browse
```sh
az aks browse --resource-group=k8s-gov \
--name=k8s-gov
```
Note:
___
<!-- .slide: id="aks-deletion" data-transition="concave" -->
# AKS Cluster Deletion
```sh
az aks delete --name k8s-gov \
--resource-group k8s-gov
```
Note:
___
<!-- .slide: id="aks-iac" data-transition="concave" -->
# AKS Infra as Code
* Manage AKS state in code
* Not as extensive as ACS Engine
* Leverage Service Principal / Key Vault
[govcloud/aks-iac](http://github.com/govcloud/aks-iac) <i class="fa fa-github"></i></li>
Note:
___
<!-- .slide: id="aks-weaknesses" data-transition="concave" -->
# AKS Weaknesses
* Can't customize **ApiServer** options
* Custom vnet support
* Slightly slower then **ACS** to get updates
* Windows support (mid-2018)
Note:
---
<!-- .slide: id="azure-acs" data-transition="concave" -->
# ACS
* Managed Kubernetes environment
* No charge for control plane
* Auto Upgrades
* Quick and efficient scaling
Note:
The easiest way to manage and operate your Kubernetes environments.
This service features an Azure hosted control plane, automated upgrades, self-healing, easy scaling and a simple UX for both developers and cluster operators.
You will never be billed for the management infrastructure which includes the K8S control plane.
Additionally AKS itself is free and you will only pay for the Nodes (VMs) that are added.
---
<!-- .slide: id="azure-acs-engine" data-transition="concave" -->
# ACS Engine
* OS core of ACS / AKS
* Allows for deep customization of K8S
* Quickest to get K8S upstream updates
Note:
___
<!-- .slide: id="acs-engine-cluster" data-transition="concave" -->
# ACS Engine Cluster Definition
* ARM templates generated via cluster spec
* Many examples exist in ACS Engine
```sh
acs-engine generate --api-model=k8s.default.json
```
Note:
___
<!-- .slide: id="acs-engine-create-cluster" data-transition="concave" -->
# ACS Engine Definition
* Execute the generated artifacts
* Always use **azuredeploy.json** from now on
```sh
az group deployment create --name "acs" \
--resource-group "acs" \
--template-file "./_output/acs/azuredeploy.json" \
--parameters "./_output/acs/azuredeploy.parameters.json"
```
Note:
___
<!-- .slide: id="acs-engine-create-cluster" data-transition="concave" -->
# ACS Engine Scale
```sh
acs-engine scale --subscription-id <subscription-id> \
--resource-group acs \
--location eastus \
--deployment-dir _output/acs \
--new-node-count 3 \
--node-pool linuxpool1 \
--master-FQDN <fqdn>
```
Note:
---
<!-- .slide: id="oms" data-transition="concave" -->
# Logging OMS
Generate base encoded string:
```sh
printf '{ "WSID": "<oms-wsid>",
"KEY": "<oms-workspace-key"
}' | base64 -w0
```
json to Cluster Definition:
```sh
{
"name": "microsoft-oms-agent-k8s",
"version": "v1"
"extensionsParameters": "<base64-coded-string>"
}
```
Note:
---
<!-- .slide: id="ark" data-transition="concave" -->
# ARK
* Disaster recpvery for K8S
* Backups cluster resources
* Backups persistent volumes
Note:
___
<!-- .slide: id="ark-backup-app" data-transition="concave" -->
# Backup Application
```sh
ark backup create jenkins-backup --selector app=jenkins-jenkins \
--snapshot-volumes
```
Note:
___
<!-- .slide: id="ark-backup-cluster" data-transition="concave" -->
# Backup Cluster
```sh
ark backup create cluster-wide --exclude-namespaces=kube-system,heptio-ark \
--snapshot-volumes
```
Note:
___
<!-- .slide: id="ark-backup-scheduled" data-transition="concave" -->
# Scheduled Backup
```sh
ark schedule create gitlab-backup --selector app=gitlab-gitlab \
--snapshot-volumes \
--schedule "0 7 * * *"
```
Note:
---
<!-- .slide: id="workflows" data-transition="concave" -->
# Researched Workflows
* CI/CD
* Data Science
* Zero to JupyterHub K8S
* Spark
* Hadoop / HDFS / Hive
* Pachyderm
* NDM / .NET
Note:
---
<!-- .slide: id="workflows-ci" data-transition="concave" -->
# CI/CD
* Jenkins w/Kubernetes plug-in
* GitLab w/GitLab CI
* Configuration as code (jobs, init scripts)
* Jenkinsfile
Note:
___
<!-- .slide: id="workflows-jenkins-examples" data-transition="concave" -->
# Some Examples
* Active Directory w/Matrix authorization
* Automated golden image provisioning
* Virtualbox node selection from Jenkins
* Packer + Azure
Note:
___
<!-- .slide: id="workflows-jenkinsx" data-transition="concave" -->
# Jenkins X
* CI/CD solution for modern cloud applications on Kubernetes
* Environment Promotion via GitOps
* Pull Request Preview Environments
* Easy to install on any cloud / on-premise
Note:
Each team gets a set of Environments. Jenkins X then automates the management of the Environments and the Promotion of new versions of Applications between Environments via GitOps
Jenkins X automatically spins up Preview Environments for your Pull Requests so you can get fast feedback before changes are merged to master
If all you do please just watch the 9 min demo video on the projects website.
---
<!-- .slide: id="workflows-jupyterhub" data-transition="concave" -->
# Zero to JupyterHub w/K8S
* Reproducible deployments of JupyterHub
* Data8 Program at **UC Berkeley**
Note:
JupyterHub is a tool that allows you to quickly utilize cloud computing infrastructure to manage a hub that enables your users to interact remotely with a computing environment that you specify.
JupyterHub offers a useful way to standardize the computing environment of a group of people (e.g., for a class of students or an analytics team), as well as allowing people to access the hub remotely.
___
<!-- .slide: id="workflows-jupyterhub-arch" data-transition="concave" -->
# Architecture
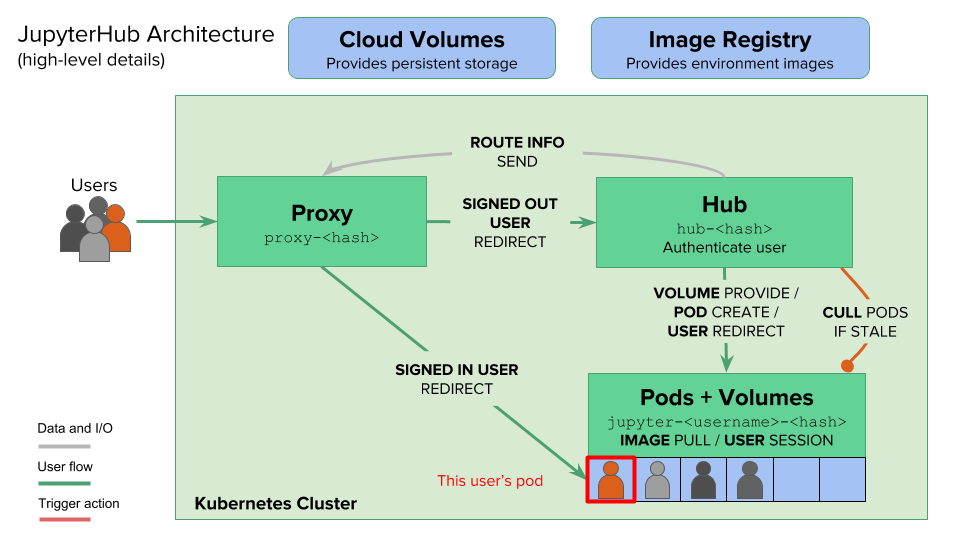
Note:
The JupyterHub Helm Chart manages resources in the cloud using Kubernetes. There are several moving pieces that, together, handle authenticating users, pulling a Docker image specified by the administrator, generating the user pods in which users will work, and connecting users with those pods.
___
<!-- .slide: id="workflows-jupyterhub-helm" data-transition="concave" -->
# Helm
```sh
helm install jupyterhub/jupyterhub \
--version=v0.6 \
--name=jupyter \
--namespace=jupyter \
-f values.yaml
```
Note:
---
<!-- .slide: id="workflows-spark" data-transition="concave" -->
# Spark
* Spark enhanced w/K8S scheduler back-end
* Spark drivers / executors in Pods
* Spark-submit used to inject params
* Carries out computation associated with Job
Note:
With the numerous advantages of containers and orchestrators being in the distributed computing domain, the Big Data world, which extensively relies on enormous amounts of distributed computing power have taken notice over the past couple years.
Particular companies such as:
* Google
* Red Hat
* Comcast
* Intel
* Palantir
* Bloomberg
* PepperData
* TerraData
Have solved many of the barriers that initially thwarted containers from thriving in the Big Data ecosystem.
The high level idea is to integrate Kubernetes as a cluster scheduler backend within Spark. This
enables Spark to directly be aware of Kubernetes in a manner similar to its awareness of
Mesos, YARN and Standalone clusters. Spark-submit is made aware of new options that are
used to inject the right parameters and create the driver and executor within Kubernetes that
carry out the computation associated with the Spark Job.
This integration between Spark and Kubernetes allows both components to interact with each
other intelligently. For instance, it allows Spark to leverage Kubernetes constructs that facilitate
authentication, authorization, resource allocation, isolation and cluster administration. Similarly,
framework level events in the cluster orchestration layer can be interpreted appropriately by
Spark. Furthermore, features like CustomResources can be used to extend the Kubernetes API
to control Spark jobs using the Kubernetes control plane.
## Spark on k8s
* Patching up Spark Driver and Executor Code
* Often times Spark stores data on HDFS
* Show different aspects of Spark ecosystem in k8s
* Spark cluster
* Spark on k8s
* Spark operator
## Comparison with Spark Standalone on Kubernetes
The proposed design is more flexible than the basic Kubernetes Spark example for several
reasons:
1. Spark executors can be elastic depending on job demands, since spark can speak directly to kubernetes in order to provision executors as required.
2. The proposed solution allows leveraging of Kubernetes constructs like ResourceQuota, namespaces, audit logging, etc. Contrasting with Spark standalone where Spark’s notion of identity is disparate and unaware of Kubernetes constructs like service accounts.
3. The proposed solution allows for greater isolation between Spark Jobs than standalone mode, as each of them runs in their own container, utilizing cgroups to enforce CPU and memory requests and limits.
4. When submitting jobs against a standalone Spark cluster running on Kubernetes, one is restricted to using the Docker image that the standalone Spark cluster was launched with to run the executors. The proposed design allows the user to specify a custom docker image for the driver and executors when the user submits the job.
5. The proposed design simplifies the process of running Spark jobs: while the current solution requires two steps to first run the standalone Spark cluster and then to run the Spark jobs against that cluster, the proposed design requires no prior k8s setup to run the user's application.
6. The proposed solution adds a Resource Staging Server (RSS) component that simplifies the deployment of user-specified jars and files which is still difficult with a Spark Standalone cluster on Kubernetes.
7. In the existing solution, resource negotiation for spark jobs is tied to the configuration of the standalone Spark cluster as well as the configuration of the Kubernetes cluster. If the second layer of the standalone cluster manager is eliminated, then the user can unify all resource administration and configuration into the Kubernetes framework alone.
8. Kubernetes is a popular container orchestration environment with wide adoption. Users who are already deploying applications on Kubernetes, or who plan to, will benefit from the ability to run Spark applications on Kubernetes as well, instead of running a separate standalone Spark cluster or managing a separate orchestration environment.
___
<!-- .slide: id="workflows-spark" data-transition="concave" -->
# Spark
```sh
bin/spark-submit \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--master k8s://https://<master>.hcp.eastus.azmk8s.io:443 \
--kubernetes-namespace default \
--conf spark.executor.instances=1 \
--conf spark.app.name=spark-pi \
--conf spark.kubernetes.driver.docker.image=kubespark/spark-driver:v2.2.0-kubernetes-0.5.0 \
--conf spark.kubernetes.executor.docker.image=kubespark/spark-executor:v2.2.0-kubernetes-0.5.0 \
local:///opt/spark/examples/jars/spark-examples_2.11-2.2.0-k8s-0.5.0.jar
```
Note:
---
<!-- .slide: id="workflows-hadoop" data-transition="concave" -->
# Hadoop
* HDFS
* HIVE
```sh
helm install --namespace hadoop \
--name hadoop $(tools/calc_resources.sh 50) .
```
Note:
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation.
## HDFS on k8s
* Data locality
* Rack locality
* Node preference
* Kerberos
* Namenode High Availability
## Why deploy Hadoop in Containers?
1) You are heavily over provisioned. You run Hadoop clusters in silos, and every time you need to bring up a silo, you create a new physical (cloud or on prem) hardware footprint to host this Hadoop cluster. Virtualization is not an option, since you want to get bare-metal performance. You have unused clusters that are consuming storage and compute resources. Since they are pinned to physical infrastructure, it is difficult to reuse resources.
2) You desire to host a common platform as a service for multiple Hadoop end users (internal customers). You also want to run other data services like Cassandra on this same infrastructure.
3) Your HDFS data lakes have inconsistencies. Since you create multiple silos for each Hadoop cluster, you are unable to audit or validate the correctness of the data in the data lakes. Since these data lakes are created separately from the deployment of your Hadoop cluster, you have no control over the governance of its data.
4) You are spending too much time with manual resources used to create silos. Your end users are unable to deploy Hadoop clusters without IT intervention and out of band compute and storage provisioning. You want to get to a mode where clusters can be deployed in a self-service, programmatic manner.
Traditionally, Hadoop has been deployed directly on bare metal servers in a siloed environment. As the number of Hadoop instances and deployments grow, managing multiple silos becomes problematic. The specific issues with managing multiple Hadoop silos on fixed physical infrastructure are:
* Under utilization of server and storage resources.
* Manual out of band storage and compute provisioning for each new deployment.
* Creation of multiple conflicting data lakes (data inconsistencies between silos).
* Zombie resources after the completion of a job.
Typically, some form of virtualization is needed to manage any large application deployment to solve these issues. Virtual machines however add a layer of overhead that is not conducive to big data deployments. This is where the advent of containers becomes useful. By deploying Hadoop inside of Linux containers, you can get the power of virtualization with bare metal performance. You also empower a DevOps model of deploying applications - one in which out-of-band IT is not involved as your application owners deploy and scale their Hadoop clusters.
The benefits of running Hadoop with containers are:
* Enable Hadoop to run on a cloud-native storage infrastructure that is managed the same way, whether you run on-premise or in any public cloud
* Faster recovery times during a failure for Data, Name and Journal nodes.
* Increased resource utilization because multiple Hadoop clusters can be safely run on the same hosts
* Improved Hadoop performance with data locality or hyperconvergence
* Dynamic resizing of HDFS volumes with no downtime
* Simplified installation and configuration of Hadoop
___
<!-- .slide: id="workflows-hadoop-scale" data-transition="concave" -->
# Scale
```sh
acs-engine scale --subscription-id <subscription-id> \
--resource-group acs-default \
--location eastus \
--deployment-dir _output/k8s-acs-default \
--new-node-count 4 \
--node-pool linuxpool1 \
--master-FQDN <fqdn>
```
Note:
___
<!-- .slide: id="workflows-hadoop-update" data-transition="concave" -->
# Update
```sh
helm upgrade hadoop --namespace hadoop $(tools/calc_resources.sh 50) .
```
Note:
---
<!-- .slide: id="workflows-pachyderm" data-transition="concave" -->
# Pachyderm

> The open source data pipelining and data management layer for K8S.
Note:
* Hadoop hard to find at Strata
* According to Gartner Hadoop is dead
___
<!-- .slide: id="pachyderm-data-versioning" data-transition="concave" -->
# Data Versioning
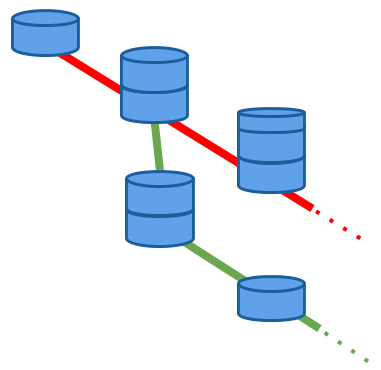
Note:
All of the data that flows into and out of a Pachyderm Pipeline stage is version controlled. You can look back to see what your training data looked like when a particular model was created or how your results have changed over time.
What Git does, in terms of Collaboration and Reproducibility, for code, Pachyderm does for your data. Collaborate on the same data with teammates and ensure that your analyses are kept in sync with the latest changes to data, or backtest models on historical states of data.
___
<!-- .slide: id="pachyderm-containers-analysis" data-transition="concave" -->
# Containers for Analysis
Note:
Data scientists utilize a diverse set of tools, languages, and frameworks. Because Pachdyerm utilizes software containers as the main element of data processing, data scientists and data engineers can use and combine any tools they need for a certain set of analyses or modeling.
Data scientists can develop code locally (e.g., in Jupyter) on samples of data and utilize that exact same code in a Docker image as a stage in a distributed Pachyderm pipeline. They don't need to import special libraries or add complication. They just declare what processing needs to be run on what data, and Pachyderm takes care of the details.
___
<!-- .slide: id="pachyderm-dag" data-transition="concave" -->
# Distributive Processing
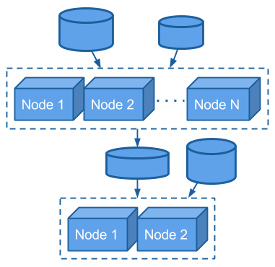
Note:
Pachyderm automatically parallelizes your analyses by providing subsets of data to multiple instances of your code. Data scientists don't have to worry themselves with explicit implementations of parallelism and data sharding in their code. They can keep their code simple (even single threaded) and let Pachyderm worry about the complications of distributed processing.
Data scientists can even declare types of nodes that should run their analysies (e.g., GPUs). Pachyderm will make sure that the right data get processed by the right types of nodes, and it will even help you auto-scale resources as your team or workloads grow or shrink.
___
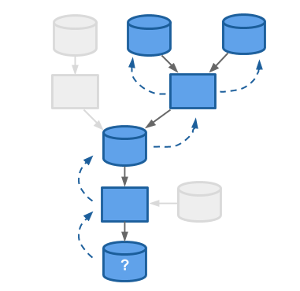
<!-- .slide: id="pachyderm-provenance" data-transition="concave" -->
# Provenance
Note:
Not all changes to code or data produce the expected results, and it can be super difficult to figure out what changes to code or data produced what results, especially as data science teams grow. Pachyderm makes this super easy!!
Pachyderm let's you quickly and easily understand the provenance of any result or intermediate piece of data. For example, you can quickly deduce which version of a model produced certain results and determine which training data was used to build that model. This let's data science teams iteratively build, change, and collaborate on analyses, while ensuring that they can debug, maintain, and understand those analyses over time.
___
<!-- .slide: id="pachyderm-helm" data-transition="concave" -->
# Helm
```sh
helm install --namespace pachyderm \
--name pachyderm \
--set pachd.image.tag=1.7.0rc2 \
--set pachd.worker.tag=1.7.0rc2 stable/pachyderm
```
Note:
___
<!-- .slide: id="pachyderm-dashboard" data-transition="concave" -->
# Dashboard
```sh
pachctl deploy local --dashboard-only \
--namespace pachyderm
```
```sh
pachctl -k '-n=pachyderm' port-forward &
```
Note:
___
<!-- .slide: id="pachyderm-opencv" data-transition="concave" -->
# OpenCV
Create images repository:
```sh
pachctl create-repo images
pachctl list-repo
```
Put image inside repository:
```sh
pachctl put-file images master liberty.png -c -f http://imgur.com/46Q8nDz.png
pachctl list-commit images
pachctl get-file images master liberty.png | open -f -a /Applications/Preview.app
```
Note:
___
<!-- .slide: id="pachyderm-opencv-2" data-transition="concave" -->
# OpenCV
Create Pipeline:
```sh
pachctl create-pipeline -f https://bit.ly/2Gx10ZU
```
See jobs kicked off:
```sh
pachctl list-job
pachctl list-repo
```
Output:
```sh
pachctl get-file edges master liberty.png |
open -f -a /Applications/Preview.app
```
Note:
___
<!-- .slide: id="pachyderm-got" data-transition="concave" -->
# Tensorflow
* Generation of GoT scripts
* Adapting LSTM Neural Net
* Low Perplexity
```sh
make input-data
make run
```
Note:
---
<!-- .slide: id="workflows-ndm" data-transition="concave" -->
# NDM
* Contributing to official Drupal Docker
* Initial Helm Chart prototype created
* PHP-FPM, NGINX, MySQL, Drupal
* Stateful Application improvements
Note:
---
<!-- .slide: id="workflows-net" data-transition="concave" -->
# .NET
* Docker for Windows + Kubernetes
* .NET Core / Framework
* Nuget Server running on Kestrel
* Tight integration in VSCode + Visual Studio
Note:
And with that I thought I would leave you with a bit of a teaser.
We are also cautiously moving forward into the Windows realm!
Actually one of my co-workers Mark Tessier is focused on delivering a refined CI / CD using at least part of these technologies