<!-- .slide: id="intro" data-transition="concave" -->
# Cloud Native Meetup
[github.com/govcloud](https://github.com/govcloud) <i class="fa fa-download"></i></li>
Note:
This is a presentation created in conjunction with the Canadian Digital Services and Cloud Operations team at Statistics Canada.
---
<!-- .slide: id="agenda" data-transition="concave" -->
# Agenda
* Planning Items
* Azure AKS / ACS Engine
* Auto Scaler
* ARK Disaster Recovery
* Distributed Logging
* Securing Helm
Note:
The agenda for today is to keep things a bit more straightforward (even though I said that last week).
Some constructive criticism already recieved was jumping around topics a bit which for the first meeting to form a broad base is fine but less ideal for meetings going onwards.
I'll be presenting one more time for this meetup but we have two volunteers for each subsequent meetup.
This excites me greatly!
For my presentation today I will just be talking from a Kubernetes Enginner / Stack Developer perspective.
---
<!-- .slide: id="planning" data-transition="concave" -->
# Planning Items
* Scope
* Methods of communication
* Virtual meetups
* Subsequent presentations
* Miscellaneous
Note:
## Planning Items
But first we need to quickly go over some highlight from the minutes during the last meetup.
* Developers / Policy makers need to work together equally
* Long road not everything can be cloud native
* IaaS formulas, Amazon, Azure, etc. is not cloud native
* Want to potentially guide procurement. (ASF, Pivotal, OpenShift)
* Code of Conduct: CNCF Code of Conduct
* Discussion around allowing vendors to share expertise
* Alignment with GC Cloud working group (share things / workflows)
* Read the rest online
### Scope
* Our primary goals is only purely cloud native
* Ignore standard IaaS, cloud-specific technology (Maybe how maps to cloud-agnostic technology)
* Hybrid cloud - solutions should work on Amazon, Azure, OpenStack, Bluemix, etc.
* Follow Canada’s Open First White paper
* Skunkworks style type group focusing on problem solving
* Would be nice to host some of the foundational containers at GoC level (GC Tools, etc)
* CNCF uses an open-source software stack:
* containerized
* dynamically orchestrated
* microservices orientated
### Communication
* Rocketchat: message.gccloud.ca (runs in a container)
* Youtube: youtube.com govcloud can access the link from website (go over videos and say will be expanding quickly)
* Website: govcloud.ca (hugo powered static site, P.R. welcome, documentation coming soon being ported from confluence)
* Meetup: meetup.com/goc-cloud-native
* Hangouts / Webex (using hangouts for now till hear complaint)
* Complete virtual meetups are welcome for smaller meetings, but perhaps with warning
## Future Presentations
* Laurent Goderre: Co-Maintainer of the Node.js docker image will be talking about his improvements to the container as well as multi stage builds.
* Zachary Seguin: Will be talking about his work with OpenFaaS, Serverless Functions Made Simple for Docker and Kubernetes and how he leveraged react to accomplish some nifty things
* Marc Tessier: Will be preaching the good work about Windows container development and his work in the .NET / Nuget space. As well as his refined CI/CD workflow from local development all the way up to the Kubernetes cluster
## Questions
* Working group video will be up on our youtube channel, however, questions about video editing
* cut off planning items and only show demo, we have minutes for other stuff
* split into clips?
* What applications are people considering containerizing? I'd love some examples?
* Anything else missing?
---
<!-- .slide: id="azure-aks" data-transition="concave" -->
# AKS
* Managed Kubernetes environment
* No charge for control plane
* Auto Upgrades
* Quick and efficient scaling
Note:
Azure Container Service (AKS) manages your hosted Kubernetes environment, making it quick and easy to deploy and manage containerized applications.
It also eliminates the burden of ongoing operations and maintenance by provisioning, upgrading, and scaling resources on demand, without taking your applications offline.
This service features an Azure hosted control plane, automated upgrades, self-healing, easy scaling and a simple UX for both developers and cluster operators.
You will never be billed for the management infrastructure which includes the K8S control plane.
Additionally AKS itself is free and you will only pay for the Nodes (VMs) that are added.
___
<!-- .slide: id="aks-create" data-transition="concave" -->
# AKS Cluster Creation
```sh
# create resource group
az group create -n aks-k8s-gov -l "eastus"
# create cluster
az aks create --name aks-k8s-gov \
--resource-group aks-k8s-gov \
--location eastus \
--node-count 1 \
--node-vm-size Standard_D4s_v3 \
--generate-ssh-keys \
--kubernetes-version 1.9.6 \
--tag aks-k8s-gov
```
Note:
The creation of the cluster is fairly straightforward but being careful to select a memory optimized server for our type of workloads (high memory to cpu).
Also if you want nested virtualization you should pick a v3 series or higher. My favorite VM based on cost / performance ratio is Standard_D4s_v3.
I will just pop over quickly to the youtube video to show how easy it is via the cli, though IMHO experience right now you might just want to go to acs-engine.
YouTube
* https://www.youtube.com/watch?v=IOhfZP6p2kg
___
<!-- .slide: id="aks-context" data-transition="concave" -->
# AKS Cluster Context
```sh
# kubectl credentials
az aks get-credentials --resource-group aks-k8s-gov \
--name=aks-k8s-gov
```
Note:
Establish kubeconfig context against current cluster.
___
<!-- .slide: id="aks-browse" data-transition="concave" -->
# AKS Cluster Browse
```sh
# kubectl proxy
az aks browse --resource-group=aks-k8s-gov \
--name=aks-k8s-gov
```
Note:
Open the Kubernetes Dashboard, similar to the kubectl proxy command.
___
<!-- .slide: id="aks-deletion" data-transition="concave" -->
# AKS Cluster Deletion
```sh
# delete cluster
az aks delete --name aks-k8s-gov \
--resource-group aks-k8s-gov
```
Note:
Tear down and delete the entire cluster based on resource group.
___
<!-- .slide: id="aks-iac" data-transition="concave" -->
# AKS Infra as Code
* Manage AKS state in code
* Not as extensive as ACS Engine
* Leverages Service Principal / Key Vault
[govcloud/aks-iac](http://github.com/govcloud/aks-iac) <i class="fa fa-github"></i></li>
Note:
Similarly to Jessica Frazelle another amazing Kubernetes developer that I highly encourage you to check out is Jessica Dean on twitter
http://jessicadeen.com/tech/aks-azure-kubernetes-service-infrastructure-as-code-iac/
She provide some initial templates that can be extended in order to deploy an AKS cluster from ARM templates.
Our repository is located under:
* https://github.com/govcloud/aks-iac
The workflow though is very similar to acs-engine in that you won't be using the cli commands from earlier slides rather an:
* az group deployment
It does also force a key vault install which is nice for increased security of the certificates etc.
___
<!-- .slide: id="aks-weaknesses" data-transition="concave" -->
# AKS Weaknesses
* Can't customize **ApiServer** options
* Custom vnet support
* Slightly slower then **ACS** to get updates
* Windows support (mid-2018)
Note:
This is largely based from personal experience:
* Can't customize the ApiServer options
* Slower then ACS / ACS Engine to recieve updates
* Missing custom vnet support
* Missing windows workload support which works great in ACS Engine
* Missing NodePool support
* Missing Virtual Machine Scale Sets
* Had some issues with it working with ACR
* Managed Self Identity (secure no creds)
* No custom script extension support currently
Though if all you want to do is deploy some applications with minimal cost that don't meet any of the restrictions it is perfect.
Though Azure Container Instances are also incredibly useful but discussion for another day.
---
<!-- .slide: id="azure-acs" data-transition="concave" -->
# ACS
* Similar to ACS
* Control over the control plane
* Auto Upgrades / Scaling
* Recieves updates faster then AKS
Note:
Azure Container Service.
Is very similar to AKS along with style of commands, except now a master will also be launched.
Unfortunately customization is minimal as well.
Usually visit the ACS-Engine repository for issues or questions regarding the use of the open-source core of ACS.
---
<!-- .slide: id="azure-acs-engine" data-transition="concave" -->
# ACS Engine
* OS core of ACS / AKS
* Allows for deep customization of K8S
* Quickest to get K8S upstream updates
Note:
The Azure Container Service Engine (acs-engine) generates ARM (Azure Resource Manager) templates for Docker enabled clusters on Microsoft Azure.
The input to the tool is a cluster definition.
The cluster definition is very similar to (in many cases the same as) the ARM template syntax used to deploy a Microsoft Azure Container Service cluster.
> For operators that need complete control and customizability of a Kubernetes cluster.
acs-engine reads a JSON cluster definition and generates a number of files that may be submitted to Azure Resource Manager (ARM). The generated files include:
* apimodel.json: is an expanded version of the cluster definition provided to the generate command. All default or computed values will be expanded during the generate phase
* azuredeploy.json: represents a complete description of all Azure resources required to fulfill the cluster definition from apimodel.json
* azuredeploy.parameters.json: the parameters file holds a series of custom variables which are used in various locations throughout azuredeploy.json
* certificate and access config files: orchestrators like Kubernetes require certificates and additional configuration files (apiserver certificates and kubeconfig)
Normally you can simply run acs-engine deploy to do a one-off cluster, however as we are building lots of clusters we are generating our templates first, and then running the deployment.
This has advantages because we can iterate over a bunch of different cluster declarations.
We can then run them through acs-engine generate to get the definitive template/params for sending to ARM.
Lets take a look at a quick video showing the workflow.
___
<!-- .slide: id="acs-engine-cluster" data-transition="concave" -->
# ACS Engine Cluster Definition
* ARM templates generated via cluster spec
* Many examples exist in ACS Engine
* Custom extensions
* Scenarios
```sh
acs-engine generate --api-model=k8s.default.json
```
Note:
Now lets discuss the types of adjustments that can be made to the cluster definition.
## Examples
* Clear Containers
* OpenShift
* Hybrid Windows
* ACI Connector
* Key vault
* GPU
* Managed Identity
* Service Mesh (istio)
* Encryption by Default
* Private Clusters
## Custom Extensions
* Choco: This extension installs packages passed as parameters via via Chocolatey package manager.
* Register DNS: Registers the Node the extension is applied against into the Azure active directory domain via nsupdate.
* Virtualbox: Extension which provisions a node with virtualbox drivers which can be leveraged via CI by Jenkins.
## Scenarios
### Custom DNS:
When there are custom dns servers k8s needs the custom dns to handle the routing and as a result /etc/resolv.conf isn't correct.
https://github.com/Azure/acs-engine/issues/1603
### Custom VNET
https://github.com/Azure/acs-engine/blob/master/examples/vnet/kubernetesvnet.json
Very important to specify the vnetSubnetId and firstConsecutiveStaticIp.
### Linux / Windows node pool
Adding a node pool
* Add (or copy) an entry in the agentPoolProfiles section in the _output/<clustername>/apimodel.json file
Removing a node pool
* Delete the related entry from agentPoolProfiles section in the _output/<clustername>/apimodel.json file
* Drain nodes from inside Kubernetes
* Generate and deploy
* Delete VM's and related resources (disk, NIC, availability set) from Azure portal
Resizing Virtual Machines in a node pool
* Modify the vmSize in the agentPoolProfiles section
* Generate and deploy
Resizing a Node Pool
* Should use acs-engine scale see in a few slides the implementation
YouTube
* https://www.youtube.com/watch?v=VuPmL25_Cls
___
<!-- .slide: id="acs-engine-create-cluster" data-transition="concave" -->
# ACS Engine Create Cluster
* Execute the generated artifacts
* Always use **azuredeploy.json** file
* Check the activity log for status
* Consider leveraging Azure Key Vault for Certs
```sh
az group deployment create --name "acs-default" \
--resource-group "acs-default" \
--template-file "./_output/k8s-acs-default/azuredeploy.json" \
--parameters "./_output/k8s-acs-default/azuredeploy.parameters.json"
```
Note:
Deployment of the cluster is relatively straight forward and can be executed again once changes are made to the api model and then regenerated.
___
<!-- .slide: id="acs-engine-create-cluster" data-transition="concave" -->
# ACS Engine Scale
```sh
acs-engine scale --subscription-id <subscription-id> \
--resource-group acs-default \
--location eastus \
--deployment-dir _output/k8s-acs-default \
--new-node-count 3 \
--node-pool linuxpool1 \
--master-FQDN <fqdn>
```
Note:
After a cluster has been deployed using acs engine the cluster can be interacted further by using the scale command.
The scale command can add more nodes to an existing node pool or remove them.
Nodes will always be added or removed from the end of the agent pool. Nodes will be cordoned and drained before deletion.
---
<!-- .slide: id="acs-autoscale" data-transition="concave" -->
# Autoscaling a Cluster
* Runs inside the cluster
* Monitors different pods that get scheduled
* Officially added in K8S v1.11 for Azure
* Amazon's is already present
Note:
This autoscaler will run inside the cluster and monitor the different pods that get scheduled.
Whenever a pod is pending because of a lack of resources, the autoscaler will create an adequate number of new VMs to support them.
Finally, when VMs are idle, the autoscaler will delete them.
That way we can achieve the flexibility we want, while still keeping costs down.
Additionally the autoscaler can also work in conjunction with the Kubernetes Horizontal Pod Autoscaling feature (discussed below)
This allows scaling based on some metrics such as CPU utilization.
In order to work properly, the autoscaler require that all the pods running on your cluster have specific resources limits defined.
This allows the autoscaler to know how much new VMs to create when some pods are pending, and which VM size fits the best.
You don't need to provide a value for all the types of resources though. Only what you explicitly need.
Now lets take a look at the youtube video.
YouTube
* https://www.youtube.com/watch?v=fB4FLfh9eSw&t=2s
---
<!-- .slide: id="ark" data-transition="concave" -->
# ARK Disaster Recovery
* Manages disaster recovery
* Backups of cluster and restore
* Copy cluster resources across clouds
* Replicate your production environments
Note:
Heptio Ark is a utility for managing disaster recovery, specifically for your Kubernetes cluster resources and persistent volumes.
Ark gives you tools to back up and restore your Kubernetes cluster resources and persistent volumes. Ark lets you:
* Take backups of your cluster and restore in case of loss.
* Copy cluster resources across cloud providers. NOTE: Cloud volume migrations are not yet supported.
* Replicate your production environment for development and testing environments.
Ark consists of:
* A server that runs on your cluster
* A command-line client that runs locally
YouTube
* https://www.youtube.com/watch?v=sHLRedoRSp0
___
<!-- .slide: id="ark-backup-app" data-transition="concave" -->
# Backup Application
```sh
ark backup create jenkins --selector app=jenkins-jenkins \
--snapshot-volumes
```
Note:
___
<!-- .slide: id="ark-backup-cluster" data-transition="concave" -->
# Backup Cluster
```sh
ark backup create cluster --exclude-namespaces=kube-system \
--snapshot-volumes
```
Note:
___
<!-- .slide: id="ark-backup-scheduled" data-transition="concave" -->
# Scheduled Backup
```sh
ark schedule create gitlab --selector app=gitlab-gitlab \
--snapshot-volumes \
--schedule "0 7 * * *"
```
Note:
---
<!-- .slide: id="logging" data-transition="concave" -->
# Distributed Logging
* Any K8S production env will rely on logs
* Extend built in capabilities
* Automate log collection and aggregration
Note:
As with any distributed system, logging provides the vital evidence for accurately tracing specific calls, even if they are on different microservices, so that a root cause of the issue(s) may be identified.
Here are our suggestions for logging within a distributed Kubernetes environment:
* Use a single, highly available log aggregator, and capture data from across the entire environment in a single place.
* Create a single, common transaction ID across the entire end-to-end call for each client.
* Ensure that service names and applications are being logged.
* Standardize the logging levels within the entire stack.
* Ensure that no data intended to be secure is being logged in the clear.
## Logging in Kubernetes
Kubernetes nodes run on a virtual Linux computing platform. Components like kubelet and Docker runtime run natively on Linux, logging onto its local system. Linux logging is configured at different folder locations including the ubiquitous /var/log file.
The first thing an administrator should do is validate log rotations for these log files, as well as all the other miscellaneous Linux logs. Kubernetes’ documentation provides good recommendations for files to rotate. The logging configuration should be inspected even if you intend to replace the local logging mechanism with an alternative.
We don’t recommend that you keep logs for virtual compute instances inside ephemeral cloud computing environments. Such instances can disappear without notice. Modern logging and analytics tools provide enough context and visual aids to help operators determine what actually transpires inside large Kubernetes cluster deployments. You should use a log aggregation service to ship your logs away from the Kubernetes environment, for later review and analysis.
## Capturing Kubernetes Logs
There are a few reliable methods for capturing Kubernetes-native Linux logs, Kubernetes container-based component logs, and all application container log data:
Simply extend Kubernetes’ existing logging capability. As logs accumulate and rotate on the nodes, you can ship them elsewhere. One popular way to do that is with a logging container whose entire purpose is to send logs to another system.
---
<!-- .slide: id="logging-efk" data-transition="concave" -->
## EFK / ELK
* Elasticsearch + Fluentd + Kibana
* Fluentd data collector
* Scalable, flexible, log / analytics pipeline
* Decouple aggregation of logs from app code
Note:
Recommend the Fluentd data collector as an alternative way to transport logs as opposed to Logstash via ELK stack (Elasticsearch, Logstash and Kibana).
Fluentd uses less memory, tag based event routing and has built in reliability.
Additionally the log shipping method makes use of the command kubectl logs.
With the concept of DaemonSets you can have a logging pod with a Fluentd container on every node.
Fluentd will be configured (via configmap) to read all the log locations for every node and aggregate them into a common searching location (residing on the node).
The common thread that is important is that we decoupled the aggregation of logs away from the application code.
This is very critical for separating the concerns of responsibility but also for performance reasons as well.
YouTube
* https://www.youtube.com/watch?v=QoHNkjtbHPg&list=PL00ZCNsWlHf65IYnlZsCl_AEj4RE2ptej
---
<!-- .slide: id="jupyterhub" data-transition="concave" -->
## JupyterHub to K8S
```sh
helm install jupyterhub/jupyterhub \
--version=v0.7-4c22c3d \
--name=jupyter \
--namespace=jupyter \
-f values.yaml
```
* Reproducible deployments of JupyterHub
* Data8 Program at **UC Berkeley**
Note:
## Background
JupyterHub is a tool that allows you to quickly utilize cloud computing infrastructure to manage a hub that enables your users to interact remotely with a computing environment that you specify.
JupyterHub offers a useful way to standardize the computing environment of a group of people (e.g., for a class of students or an analytics team), as well as allowing people to access the hub remotely.
* Reproducible deployments of JupyterHub
* Data8 Program at UC Berkeley
## Architecture
The JupyterHub Helm Chart manages resources in the cloud using Kubernetes. There are several moving pieces that, together, handle authenticating users, pulling a Docker image specified by the administrator, generating the user pods in which users will work, and connecting users with those pods.
You can see how elegant this solution is and even works with Active Directory via the LDAP Authenticator, then the moment the user logs and picks their profile it will launch the appropriate Notebook Server for the specific user along with the specific docker container selected. When the user logs out we can even set a cull policy.
Workflow
a) Proceed to the login screen
b) Select appropriate profile
Where the Spawner options is simply set via the helm config and can set the docker image as well as cpu / memory / and network constraints! You can see how the values below I have given are presented in the chart above.
c) Choice of JupyterLab / Classic Jupyter
YouTube
* https://www.youtube.com/watch?v=uijwYd8Wxzg
---
<!-- .slide: id="workflows-ci" data-transition="concave" -->
# CI/CD
* Jenkins w/Kubernetes plug-in
* GitLab w/GitLab CI
* Configuration as code (jobs, init scripts)
* Jenkinsfile
Note:
___
<!-- .slide: id="workflows-jenkins-examples" data-transition="concave" -->
# Some Examples
* Active Directory w/Matrix authorization
* Automated golden image provisioning
* Virtualbox node selection from Jenkins
* Packer + Azure
Note:
___
<!-- .slide: id="workflows-jenkinsx" data-transition="concave" -->
# Jenkins X
* CI/CD solution for modern cloud applications on Kubernetes
* Environment Promotion via GitOps
* Pull Request Preview Environments
* Easy to install on any cloud / on-premise
Note:
Each team gets a set of Environments. Jenkins X then automates the management of the Environments and the Promotion of new versions of Applications between Environments via GitOps
Jenkins X automatically spins up Preview Environments for your Pull Requests so you can get fast feedback before changes are merged to master
If all you do please just watch the 9 min demo video on the projects website.
---
<!-- .slide: id="workflows-pachyderm" data-transition="concave" -->
# Pachyderm

> The open source data pipelining and data management layer for K8S.
Note:
* Hadoop hard to find at Strata
* According to Gartner Hadoop is dead
___
<!-- .slide: id="pachyderm-data-versioning" data-transition="concave" -->
# Data Versioning
Note:
All of the data that flows into and out of a Pachyderm Pipeline stage is version controlled. You can look back to see what your training data looked like when a particular model was created or how your results have changed over time.
What Git does, in terms of Collaboration and Reproducibility, for code, Pachyderm does for your data. Collaborate on the same data with teammates and ensure that your analyses are kept in sync with the latest changes to data, or backtest models on historical states of data.
___
<!-- .slide: id="pachyderm-containers-analysis" data-transition="concave" -->
# Containers for Analysis
Note:
Data scientists utilize a diverse set of tools, languages, and frameworks. Because Pachdyerm utilizes software containers as the main element of data processing, data scientists and data engineers can use and combine any tools they need for a certain set of analyses or modeling.
Data scientists can develop code locally (e.g., in Jupyter) on samples of data and utilize that exact same code in a Docker image as a stage in a distributed Pachyderm pipeline. They don't need to import special libraries or add complication. They just declare what processing needs to be run on what data, and Pachyderm takes care of the details.
___
<!-- .slide: id="pachyderm-dag" data-transition="concave" -->
# Distributive Processing
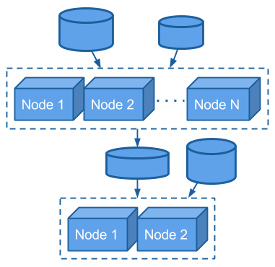
Note:
Pachyderm automatically parallelizes your analyses by providing subsets of data to multiple instances of your code. Data scientists don't have to worry themselves with explicit implementations of parallelism and data sharding in their code. They can keep their code simple (even single threaded) and let Pachyderm worry about the complications of distributed processing.
Data scientists can even declare types of nodes that should run their analysies (e.g., GPUs). Pachyderm will make sure that the right data get processed by the right types of nodes, and it will even help you auto-scale resources as your team or workloads grow or shrink.
___
<!-- .slide: id="pachyderm-provenance" data-transition="concave" -->
# Provenance
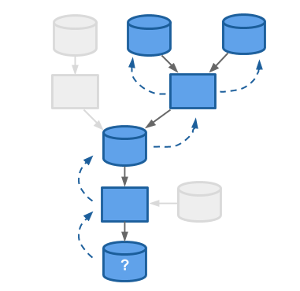
Note:
Not all changes to code or data produce the expected results, and it can be super difficult to figure out what changes to code or data produced what results, especially as data science teams grow. Pachyderm makes this super easy!!
Pachyderm let's you quickly and easily understand the provenance of any result or intermediate piece of data. For example, you can quickly deduce which version of a model produced certain results and determine which training data was used to build that model. This let's data science teams iteratively build, change, and collaborate on analyses, while ensuring that they can debug, maintain, and understand those analyses over time.
___
<!-- .slide: id="pachyderm-helm" data-transition="concave" -->
# Helm
```sh
helm install --namespace pachyderm \
--name pachyderm \
--set pachd.image.tag=1.7.0rc2 \
--set pachd.worker.tag=1.7.0rc2 stable/pachyderm
```
Note:
___
<!-- .slide: id="pachyderm-dashboard" data-transition="concave" -->
# Dashboard
```sh
pachctl deploy local --dashboard-only \
--namespace pachyderm
```
```sh
pachctl -k '-n=pachyderm' port-forward &
```
Note:
___
<!-- .slide: id="pachyderm-opencv" data-transition="concave" -->
# OpenCV
Create images repository:
```sh
pachctl create-repo images
pachctl list-repo
```
Put image inside repository:
```sh
pachctl put-file images master liberty.png -c -f http://imgur.com/46Q8nDz.png
pachctl list-commit images
pachctl get-file images master liberty.png | open -f -a /Applications/Preview.app
```
Note:
___
<!-- .slide: id="pachyderm-opencv-2" data-transition="concave" -->
# OpenCV
Create Pipeline:
```sh
pachctl create-pipeline -f https://bit.ly/2Gx10ZU
```
See jobs kicked off:
```sh
pachctl list-job
pachctl list-repo
```
Output:
```sh
pachctl get-file edges master liberty.png |
open -f -a /Applications/Preview.app
```
Note:
___
<!-- .slide: id="pachyderm-got" data-transition="concave" -->
# Tensorflow
* Generation of GoT scripts
* Adapting LSTM Neural Net
* Low Perplexity
```sh
make input-data
make run
```
Note: