<!-- .slide: id="intro" data-transition="concave" -->
# Open First Day
[github.com/statcan](https://github.com/statcan) <i class="fa fa-area-chart"></i></li>
Note:
Hi there!
This is a fun presentation for me because I get to talk about some of the open source work being done at Statistics Canada.
But more then that I get to talk about a philosophy that has been working its way in to the department and what appears to soon be the broader government as a whole.
If any Open Government people are here I just wanted to quickly say you are the best!
---
<!-- .slide: id="devs" data-transition="concave" -->
# Developers
> Modernizing app delivery for Canadians
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>William Hearn</li>
<li>@sylus <i class="fa fa-github"></i></li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Laurent Goderre</li>
<li>@LaurentGoderre <i class="fa fa-github"></i></li>
</ul>
</div>
Note:
Will:
I'm an Open Source developer of I don't want to say how many years and am currently working as a cloud engineer for the cloud operations team at Statistics Canada.
In my past I have worn many hats but primarily some people may know me from the Drupal community a platform which incidentally powers both Statistics Canada and the Open Data portal as well as many other departments across the GoC.
I've been very lucky throughout my life to have been a part of some amazing open source communities particularly because I have been able to grow so much as a developer and meet some amazing friends throughout.
As a personal note I can't really describe how it feels when you get to interact with one of your heroes in a GitHub issue.
* Jessie Frazelle from Docker
* Tianon Gravi from Docker
* Brandon Phillips from CoreOS
* Angie Byron (webchick) from Drupal
* Jonathan Pulsifer from Shopify
* Daniel Tomcej from Traefik
If you get one thing from me during this talk I hope that it is that I wholeheartedly believe that it is "All about the community".
Laurent Goderre:
ToDo: Add Laurent Introduction Text
---
<!-- .slide: id="stc" data-transition="concave" -->
# Statistics Canada
* Decade of Open Source
* Encourages Developers to Contribute
* Starting to be Open by Default
* Return on Investment
Note:
Statistics Canada has been increasing in its use of Open Source technologies over the past few years and is poised to make bigger changes over the next several which I am very excited about and will detail over the coming slides.
One of the more interesting things about this department is that (at least in my experience) it encourages developers to contribute back to their respective community and has even permitted some teams to develop completely their software in the open on GitHub.
A very special team has been doing just that for over 5+ years.
Some of you might find this to be a bit counter-intuitive at first I mean where is the direct benefit back to the department?
Lets ponder that one for a moment while I continue onwards. The suspense.
___
<!-- .slide: id="stc-use" data-transition="concave" -->
# Use of Open Source
* Angular / React.JS / Vue.js / D3.js
* Drupal
* Solr
* ELK
* Docker / Kubernetes
Note:
## Use of Open Source
I'm aware of quite a few teams leveraging frontend toolkits such as `Angular` / `React.JS` / `Vue.js` / `d3.js` performing progressive enhancement on a variety of our web applications.
* Angular.js leveraged for our upcoming search pages
* React.JS used for our Cannabis Portal
* Vue.js for generating SAS Code to the front-end user
* D3.js for our Data Visualizations (which you will soon hear about in a moment by the amazing Laurent
Brief Anectode:
* I met Laurent through the Web Experience Toolkit git repository and ever since he has taught me so much
* Incidentally without his help the wet-boew integration with platforms such as Drupal would have been much harder
* Meeting new friends is commonplace for Open Source communities
Close to my heart though is we have a stellar Web Content Management Systems team / maintainers that have been using `Drupal` for the past 5+ years and all of whom develop (for the most part) in the open.
Next we have a search team that continues to use `Apache Solr` the open source enterpise search platform (built on Apache Lucene) for much of our search and web pages.
Though I should mention the search team and some other ones are also looking at ElasticSearch mostly from an monitoring perspective via the `ELK` stack.
I will get into the ELK stack late time permitting but it is comprised of:
* ElasticSearch
* Logstash
* Kibana (D3.js)
What is perhaps the most exciting though is the amount of teams we as the Cloud Operations team assist with moving toward microservices by first containerizing their applications.
We have various teams doing this so rather then mention acronyms I will just mention the programming language which is perhaps the most relevant detail anyways.
* C#, .NET (windows)
* JS / Node.js
* Java
* GoLang
* Python
* PHP
* SAS
* Stata
Finally as an organization we along with every cloud vendor are taking quite a thorough look at what a pretty awesome person says is "the operating system of the cloud".
The answer?
Kubernetes! Which makes me pretty happy... most days...
___
<!-- .slide: id="stc-contributions" data-transition="concave" -->
# Contributions
* Bootstrap / WET-BOEW Framework
* Drupal
* Docker / Kubernetes
* Node.js
* Data Visualizations (D3.js)
* CNCF Meet-up
Note:
So Open Source doesn't exist without a community and contributions to sustain it.
Interestingly as once you start using Open Source as a agency you realize in order to maximize your benefits you often need to contribute back.
* Get yourself known in community and make friendships
* More likelihood of someone going out of their way to help you
* You will increase your own competence by engaging with community
* Will stay up to date with latest changes
* Ability to shape the product and align it to your own departments vision
The following are a list of examples I am at least aware of where Stats Can has contributed:
### `Bootstrap` and the `WET-BOEW` jQuery Framework.
### Drupal
Where we developed a `Drupal Web Experience Toolkit` platform that has been shared and leveraged by many other government departments even provincial ones.
Incidentally StatsCan played a significant role in the development of the Open Data / Open Government initiative which saw improvements being made to both `CKAN` and `Drupal` upstream.
* The Team won Public Service Excellence Awards for Open Data
* Open Data won UK Award 2018 just a few months ago
* Numerous patches provided against Drupal Core / and countless contributed modules helping the community as a whole
Finally just have to mention that the Drupal team provides support to countless other departments.
### Docker
* Improvements to Official Container images (Drupal, Node)
* Sharing our approach to Containerization (Linux, Windows) with other departments
### Kubernetes
* Improvements and additions to Official Kubernetes Helm Charts
* Sharing our approach to Kubernetes (Linux, Windows) with other departments
### Data Visualizations
* Data visualizations for public use
* Leverages customized improvements to d3.js
### CNCF Meetup
* Work with the amazing people at CDS (seriously no joke those are some of the most knowledgeable people you could ever meet) hosting the monthly GoC Cloud Native Meetups
### Personally
Personally I have been encouraged by my department as it is seen as a net benefit to contribute back to the Open Source community.
### Developer Talent
> This might be a useful point to mention here that the agency actively seeks out Open Source developer talent.
___
<!-- .slide: id="stc-roi" data-transition="concave" -->
# RoI
* Code is of higher quality
* Focus on security and abstraction
* Attract developer talent
* Operational efficiency
Note:
I just wanted to quickly mention that we realized early on there is a lot of benefit to leveraging Open Source and it brings with it a significant return on investment.
For instance when you develop in the open:
* Your code is of higher quality and usually goes through some sort of linting, building through CI (circle, travis, etc)
* More focus is placed on security and abstraction
* Ability for others to peer review and improve your code (Personally this has been really valuable to me)
* Attract developer talent
Open Source Developers have options and a range of choices and the first thing they do will be to look at some of your public repos.
For instance, thanks to Laurent's d3.js work we are getting an exceptional data visualization expert that has studied at MIT.
For myself, thanks to some of the Drupal's team open source work, we managed to snag a brilliant developer straight out of Waterloo (not today private companies) who is personally the most knowledgeable developer I have ever worked with and has become my best friend.
Anyways these types of talent coming into your department drive new energy and innovation.
When you leverage high quality Open Source projects **with thriving communities**:
* Innate ability to improve the software
* Gain Exceptional support from passionate people
* Operational efficiency with speed of execution
I think Statistics Canada is heading in the right direction but there is still a lot more work to do so expect to see the following from us!
* Open Source our Cannabis Platform and make available for P.R.
* More consolidation of our disparate open source repositories work under official repository
* Drupal
* JS Tools
* Design Patterns and UX Research
* Showcasing of our new API (jsonAPI) which Laurent will soon be talking about
* A few of our internal golang applications created to solve specific problems with data holdings
---
<!-- .slide: id="dataviz-intro" data-transition="concave" -->
# DataViz at StatsCan
* Open Source and Format(s)
Note:
___
<!-- .slide: id="dataviz-why-os" data-transition="concave" -->
# Why Open Source?
> It's about more then free software
* Training opportunity for GC employees
* Helps staff stay up-to-date on new tech
* Attract talent
Note:
___
<!-- .slide: id="dataviz-why-open-formats" data-transition="concave" -->
# Why Open Formats?
> Developing in the open
* Easier to mashup data with other sources
* Enables 3rd party developers to create own data
* Decreate learning curve for using out data
Note:
___
<!-- .slide: id="dataviz-stack" data-transition="concave" -->
# DataViz OS Stack
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li class="list-unstyled"><img src="/img/architecture/openfirst/docker-icon.png" height=200px></img></li>
<li class="list-unstyled"><img src="/img/architecture/openfirst/d3js-icon.png" height=200px></img></li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li class="list-unstyled"><img src="/img/architecture/openfirst/nodejs-icon.png" height=200px></img></li>
<li class="list-unstyled"><img src="/img/architecture/openfirst/i18next-icon.png" height=200px></img></li>
</ul>
</div>
Note:
___
<!-- .slide: id="dataviz-formats" data-transition="concave" -->
# Open Formats
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li class="list-unstyled"><img src="/img/architecture/openfirst/jsonapi-icon.png" height=200px></img></li>
<li class="list-unstyled"><img src="/img/architecture/openfirst/schema-icon.png" height=200px></img></li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li class="list-unstyled"><img src="/img/architecture/openfirst/json-ld.png" height=200px></img></li>
<li class="list-unstyled"><img src="/img/architecture/openfirst/iso-icon.png" height=200px></img></li>
</ul>
</div>
Note:
---
<!-- .slide: id="drupal-community" data-background-image="/img/architecture/openfirst/drupal-community.jpg" -->
Note:
So there is a quote I like from the creator of Drupal: Dries Buytaert
"It’s really the Drupal community and not so much the software that makes the Drupal project what it is. So fostering the Drupal community is actually more important than just managing the code base."
This is because the Drupal community has perhaps the most passionate userbase around which constantly helps to develop, maintain and create new Drupal functionality. While adhering to high technical standards of UX, architecture, and accessibility.
It should also be reminded that Drupal is and always be free and that the platform will always be available at no cost and one need only compare this with other content management system that can cost hundreds and thousands of dollars to purchase and license. While still only having a fraction of the functionality that is in Drupal 8.
Finally If you look back at Drupal’s history, the platform alao does a great job of addressing security issues. A bulletin is released to Drupal users whenever there is an issue with the platform or when and there are updates to fix the problem.
Additionally there is a dedicated Drupal security team that works to monitor potential security risks.
Some people worry whether an open source system is easier to hack? The reality, though, is that with a team of users and dedicated security experts it is likely the best defense you can have.
___
<!-- .slide: id="drupal-main" data-transition="concave" -->
# Drupal
> Enterprise Content Management System and Application Development Framework
<div class="col-xs-6 col-sm-6 col-md-6">
<ul>
<li>Rich Data Modeling</li>
<li>Content Architecture</li>
<li>Config Management</li>
<li>SEO</li>
<li>Multilingualism</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul>
<li>ACL</li>
<li>jsonAPI, GraphQL</li>
<li>Workspaces</li>
<li>Accessibility</li>
<li>React.js</li>
</ul>
</div>
Note:
So I am only going to talk about Drupal at a high level as there is a full demonstration at 3:30 being given by Robin Galipeau showing Drupal using the Web Experience Toolkit with Apache Solr.
The following just represents some bullet points of the features I consider important but it might be better to split it up by persona.
___
<!-- .slide: id="drupal-content-authors" data-transition="concave" -->
# Content Authors
> **Drupal 8** provides the following features built-in for authoring
1. Accessibility / SEO
2. HTML5 / Mobile First
3. Multilingual
4. Quick Edit
5. Content Workflow / Staging
Note:
For Content authors there is often a range of concerns but at top of mind is probably accessibility.
Your in luck though because Drupal (particularly Drupal 8) is the most accessibile CMS/CMF without exception.
There are many instances in Drupal 8 where it has been able to provide more semantic HTML5 elements which assistive technology will be able to leverage.
This has been extended further by adding WAI-ARIA landmarks, live regions, roles & properties. Other features such as Aural Alerts, Controlled Tab Order, Alt Text required by default, and Accessible Inline Form Errors where it is easier for everyone to identify what errors they might have made when filling in a web form.
Then for Mobile First you have that every single theme is responsive and even the administration toolbar was optimized for mobile.
Most impressively Drupal is extensively Multilingual and supports over 154 languages where you can assign a language to every possible context in the system. You will also benefit from the automated downloads and updates of official translations, that will never override your protected local ones. Finally for content you get field level configurability and fine grained per language content access.
For content and every entity in Drupal there is built in revision support, with improved moderation transition handling and thanks to the Deploy suite of modules you can easily deploy your content across Drupal sites via REST. This is important for more restricted environments like Statistics Canada where the content can't even reside on the database in production behind a draft status until the approved time.
Deployment is actually really neat in Drupal 8 as it allows you to have things like:
* Cross Site Content Staging
* Content Branching via a git like paradigm
* Workspaces for your site to preview
* Offline browse and publish capabilities
* Content Recovery and Full Audit logs
I encourage you to take a look at drupaldeploy.org if interested in how it works but I have grabbed a quick video to illustrate.
Apologies as I wanted to do it in our platform using the GoC Canada theme but didn't have time ^_^
___
<!-- .slide: id="drupal-workspace-preview" data-transition="concave" -->
Content Staging
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/3JwkLA--Ciw" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
Note:
> Demo: Content Staging
___
<!-- .slide: id="drupal-developers" data-transition="concave" -->
# Developers
> **Drupal 8** is an enterprise `CMS/CMF` built with developers in mind:
1. Data Modeling
2. Config Management / Typed Schema
3. ACL (roles / permissions)
4. Web Services
5. Dev Tools
6. Templating / Progressive Enhancement
Note:
> SKIP: Due to time constraints I will skip this slide.
Drupal is exceptional at Content Architecture and that is facilitated through how it models data via the Entity System.
Without getting too technical the Entity system lets you have different types of configuration and content entities where you can add revisions, translations and fields.
The Configuration API provides central place to store configuration data.
It should be noted that all configuration data represents the whole state of the site can be easily exported between sites.
Additionally all configuration must align to a schema which describes its structure and is typecasted for consistency.
A novel feature that developers appreciate is that you can easily sync between configuration from yaml to a 1 to 1 mapped database table.
The last thing I will mention is that thanks to Drupal Entity system it is truly api first as you have the ability to expose anything in the platform as a full RESTful service using either JSONAPI or GraphQL.
This lends itself greatly for those amazing frontenders who just want to recieve json and full control of the markup.
Finally I just wanted to mention what happened most recently with Drupal 8 integrating with React.js and taking progressive enhancement to the forefront.
___
<!-- .slide: id="wxt-d7" data-transition="concave" -->
WxT D7 <!-- .element: class="col-xs-3 col-sm-3 col-md-3 bg-primary" -->
A installation profile which relies on and integrates extensively with the
WET-BOEW jQuery Framework.<!-- .element: class="col-xs-9 col-sm-9 col-md-9 text-left" style="padding-left: 1em; padding-bottom: 1em;" -->
* 5+ years operational track record
* 20+ departments leveraging
* National collaboration with some provinces / municipalities
* Incredibly stable platform for development
* WET4 Implementation
* A lot of lessons learned
Note:
> Demo WetKit: https://www.drupal.org/project/wetkit
> Demo WetKit: https://github.com/wet-boew/wet-boew-drupal
So this brings us to Statistics Canada's open source Drupal 7 variant of the Web Experience Toolkit where there has been:
* 5+ years providing security updates to downstream 20+ departments
* 5+ years offering support and help in our issues queues to everyone
* 5+ years showing the value of proper content architecture
I'm incredibly proud that we managed to get some national collaboration with some provinces and municipalities though there were many lessons learned on the way.
___
<!-- .slide: id="wxt-d7-success" data-transition="concave" -->
# WxT D7: Success Story?
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled">Industry Can</li>
<li class="list-unstyled">TBS</li>
<li class="list-unstyled">FinTrac</li>
<li class="list-unstyled">PCO/CDS</li>
<li class="list-unstyled">VAC</li>
<li class="list-unstyled">SSC</li>
<li class="list-unstyled">SCC</li>
</ul>
</div>
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled">Health Can</li>
<li class="list-unstyled">CIHR</li>
<li class="list-unstyled">CSE</li>
<li class="list-unstyled">RCMP</li>
<li class="list-unstyled">OCOL</li>
<li class="list-unstyled">CTA</li>
<li class="list-unstyled">Buy and Sell</li>
</ul>
</div>
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled">PMO</li>
<li class="list-unstyled">PCO</li>
<li class="list-unstyled">Hamilton</li>
<li class="list-unstyled">PEI</li>
<li class="list-unstyled">CATSA</li>
<li class="list-unstyled">CMHR</li>
<li class="list-unstyled">Science.gc.ca</li>
</ul>
</div>
Note:
I thought I would just throw up a list of some of the sites I know that have used Drupal WxT. Most represent success stories but as we are a small team can't say there weren't a few bumps in the road for a few of these sites. However, thanks to everything being open source the failures from earlier projects always have components that can readily be used to increase the odds of success for the next project.
___
<!-- .slide: id="lightning" data-transition="concave" -->
Lightning<!-- .element: class="col-xs-3 col-sm-3 col-md-3 bg-primary" data-fragment-index="1" --> <i class="fa fa-bolt"></i>
Lightning's mission is to enable devs to create great authoring
experiences and empower editorial teams.<!-- .element: class="col-xs-9 col-sm-9 col-md-9 text-left" data-fragment-index="2" style="padding-left: 1em; padding-bottom: 0.25em;" -->
- Minimal opt-in design
- Extensively tested + secured @ [Acquia](http://lightning.acquia.com/)
- Targets several key functional areas:
* Media
* Layout
* Workflow
* API-First
Note:
> Lightning: https://www.drupal.org/project/lightning
We learned a lot of lessons in Drupal 7 and from maintaning an open source project over so many years
The main lesson was to delegate some of the work we were handling and increase the amount of community collaboration.
This is where Lightning comes in.
Lightning is a top Distribution in Drupal 8 backed by Acquia allowing you to build experiences quickly using the best of Drupal 8 in a feature rich, extensively tested, and secure open source distribution. Lightning powers huge sites such as:
* Princeton
* Tesla
* Pfizer
4 key functional areas are targeted:
* Drag and Drop Layouts: Configure page layouts with drag and drop tools.
* Media Management: Embed images, videos, instragram, twitter and more from Drupal or other sources into content and pages.
* Workflows: Configure workflows that keep content moving through review and approval stages, easily.
* API First: Lightning ships with several modules which, together, quickly set up Drupal to deliver data to decoupled applications via a standardized API. Toolkit for authentication, auth, and delivery of data to API consumers.
Progressive Enhancements now that React.js is in core is also being added.
* Scheduler
___
<!-- .slide: id="lightning-layout-builder" data-transition="concave" -->
Layout Builder
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/gsRyGgZMWaw" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
___
<!-- .slide: id="wxt-d8" data-transition="concave" -->
WxT D8<!-- .element: class="col-xs-3 col-sm-3 col-md-3 bg-primary" -->
A sub-profile of Lightning which relies on and integrates extensively with the
WxT jQuery Framework.<!-- .element: class="col-xs-9 col-sm-9 col-md-9 text-left" style="padding-left: 1em; padding-bottom: 1em;" -->
- Lightweight and extensible
- Supports all WxT themes
- Improved layouts aligned to GoC IA spec
- WxT Bootstrap / Library (standalone)
- Variety of WxT Plugins ported
- Work underway for WET5
Note:
> WxT: https://www.drupal.org/project/wxt
Built with lessons learned from Drupal 7 Web Experience Toolkit. One of the biggest decisions was deciding to leverage Lightning as our base framework. This choice wasn't made carelessly but 1 year in I can say it has been an incredible time saver, allowing us to more readily focus on departmental customizations.
Following the practice of Lightning; WxT tries to keep it scope minimal and ensure when functionality is added that it can be easily disabled.
All of the various WET-BOEW themes are supported and can be toggled in either a minifed / non minified mode
We integrated with bootstrap layouts which gives us impressive grid control to support many types of layouts and we have mapped most of the layouts from the official GoC IA spec.
Drupal has also recently added ReactJS to core which nicely aligns us with some of the WET5 work being done.
We are actively working on ensuring when WET 5 launches we also provide support.
___
<!-- .slide: id="wxt-od" data-transition="concave" -->
Open Data<!-- .element: class="col-xs-3 col-sm-3 col-md-3 bg-primary" -->
A sub-profile of WxT which serves as the front-end user engagement portal for
GoC @ Open Data<!-- .element: class="col-xs-9 col-sm-9 col-md-9 text-left" style="padding-left: 1em; padding-bottom: 1em;" -->
* User Engagement
* Decoupled improvements
* CKAN / Solr integration
* Refined workflows
* Improved search
Note:
This now brings us to our Open Data sub-profile of WxT which is the first to run the Drupal 8 version of the Web Experience Toolkit in production.
> Demo: http://open.canada.ca
> Demo: Home Page where you can easily change the layout via the UI: https://open.canada.ca/en
> Demo: Blog functionality that was ported back to WxT: https://open.canada.ca/en/blog
> Demo: Apps rating and faceted support via Solr: https://open.canada.ca/en/apps
> Demo: One of 20+ search pages presented data from backend solr, but is special as sends data straight to a webform about the record https://open.canada.ca/en/search/ati
I'm really proud of this site for a few reasons:
* Helped us greatly improve our WxT base which can help all departments
* Features tight integration with CKAN + Solr:
* Leveraging jsonAPI so that CKAN can natively use Drupal's commenting, voting, and interactive features
* Search pages that are incredibly easy to create, with faceted supported and great customization
* Was delivered between 6-9 months with 2 developers working mostly full time on it.
___
<!-- .slide: id="wxt-stc" data-transition="concave" -->
Statistics Canada<!-- .element: class="col-xs-3 col-sm-3 col-md-3 bg-primary" -->
A sub-profile of WxT which serves as the front-end user engagement portal for
Statistics Canada<!-- .element: class="col-xs-9 col-sm-9 col-md-9 text-left" style="padding-left: 1em; padding-bottom: 1em;" -->
* New Dissemination Model
* Blog / Question of the Month
* Tailored workflows to department
* Content Staging / Deployment
* MyStatCan / Authenticated Apps
Note:
> Demo: Home Page where you can easily change the layout via the UI: https://www.statcan.gc.ca/eng/start
> Demo: Blog functionality: https://www.statcan.gc.ca/eng/blog
> Search Data Pages: https://www150.statcan.gc.ca/n1/en/type/data?MM=1
> Geography: https://www150.statcan.gc.ca/n1/en/geo?MM=1
Finally to close off the Drupal section thought I would just mention that Statistics Canada has used Drupal to great effect:
* Search Data Pages: Rendering data from multiple backend systems such as Solr / Oracle
* Refined Content Authoring / Publishing tailored to StatCan business requirements
* Content Staging / Deployment
* Content team can author content in a staging environment, get their verifications and approvals, then publish to a production environment
* Content abstractions to make editing and validation easier
* Theme updates and switches from previous versions of WET are relatively painless thanks to the decoupled presentation layer
___
<!-- .slide: id="wxt-ask" data-transition="concave" -->
# Future Direction
* We are looking for Open Source talent
* Progressive Enhancement / Decoupling
* WET 5 Integration
* Centre of Excellence
* More community / contributions
Note:
So this closes of the Drupal section but just wanted to mention that the Drupal team is actively looking for developers.
Additionally stay tuned for more information about the WET 5 integration, the potential for a Drupal Centre of Excellence, and some great progressive enhancements features being added thanks to React.
---
# Go
<!-- .slide: id="cloudnative-gophers" data-background-size="contain" data-background="#FFFFFF" -->

___
<!-- .slide: id="golang" data-transition="concave" -->
# Go
* Language of the cloud
* Efficient and easy to learn
* Multi Platform
* Follows the best laid path
Note:
Go is an open source programming language that is simple to learn, highly performant and remarkably powerful.
* Blazing fast and on par with a well written C program and you can write Go much faster
* The static binaries it builds are incredibly easy to deploy. Think scratch container + go app itself < 10MB
* Incredible amount of freedom but usually only one best practice way of doing something
* Don't need to prove how cool you are by doing pointer arithmetic for no other reason then you can
* Build your programs for many different platforms:
* Linux, Solaris, Mac OSX
* Windows
* BSD's on am64, i686, or ARM
* Obviously need to make sure your libraries aren't platform specific
* Backend and systems programming so much more accessible thanks to a simple elegant language:
* Profiling and Tracing tools are great
* Concurrency is built into go and so easy to work with
* Go's interfaces can take some time to wrap your brain around
___
<!-- .slide: id="golang-projects" data-transition="concave" -->
# Projects
> We use the following projects quite extensively at Statistics Canada
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>ACS Engine</li>
<li>ARK</li>
<li>Traefik</li>
<li>Grafana / Prometheus</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Hugo</li>
<li>Vault</li>
<li>Docker ++</li>
<li>Kubernetes ++</li>
</ul>
</div>
Note:
While not an exhaustive list these are a few of the projects we are actively using and taking into Production that are written in Go.
Just wanted to mention we will go over Docker and Kubernetes specificaly later in the presentation.
___
<!-- .slide: id="golang-acs-engine" data-transition="concave" -->
# ACS Engine
> For operators that need complete control and customizability of a Kubernetes cluster.
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>OS core of ACS/AKS</li>
<li>ARM templates via spec</li>
<li>Immense customization</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Custom extensions</li>
<li>Provided examples</li>
<li>Detailed scenarios</li>
</ul>
</div>
Note:
> Demo: Cluster Definitions https://github.com/Azure/acs-engine/tree/master/examples
> Extensions: Choco https://github.com/Azure/acs-engine/tree/master/extensions/choco
The Azure Container Service Engine (acs-engine) generates ARM (Azure Resource Manager) templates for Docker enabled clusters on Microsoft Azure.
The input to the tool is a cluster definition.
The cluster definition is very similar to (in many cases the same as) the ARM template syntax used to deploy a Microsoft Azure Container Service cluster.
acs-engine reads a JSON cluster definition and generates a number of files that may be submitted to Azure Resource Manager (ARM). The generated files include:
* apimodel.json: is an expanded version of the cluster definition provided to the generate command. All default or computed values will be expanded during the generate phase
* azuredeploy.json: represents a complete description of all Azure resources required to fulfill the cluster definition from apimodel.json
* azuredeploy.parameters.json: the parameters file holds a series of custom variables which are used in various locations throughout azuredeploy.json
* certificate and access config files: orchestrators like Kubernetes require certificates and additional configuration files (apiserver certificates and kubeconfig)
Normally you can simply run acs-engine deploy to do a one-off cluster, however as we are building lots of clusters we are generating our templates first, and then running the deployment.
This has advantages because we can iterate over a bunch of different cluster declarations.
We can then run them through acs-engine generate to get the definitive template/params for sending to ARM.
## Generation of ARM Templates
```sh
acs-engine generate --api-model=k8s.default.json
```
There are a variety of examples that acs-engine provides to get you started with the following:
## Examples
* Clear Containers
* OpenShift
* Hybrid Windows
* ACI Connector
* Key vault
* GPU
* Managed Identity
* Service Mesh (istio)
* Encryption by Default
* Private Clusters
Additionally ACS Engine support extensions that can provide additional logic to your cluster when deploying. We actually made and submitted the Choco extension to acs-engine.
## Custom Extensions
* Choco: This extension installs packages passed as parameters via via Chocolatey package manager.
* Register DNS: Registers the Node the extension is applied against into the Azure active directory domain via nsupdate.
* Virtualbox: Extension which provisions a node with virtualbox drivers which can be leveraged via CI by Jenkins.
The following represents a list of some common scenarios that we have been using internally at Statistics Canada
## Scenarios
Custom DNS + Custom VNET
https://github.com/Azure/acs-engine/blob/master/examples/vnet/kubernetesvnet.json
Very important to specify the vnetSubnetId and firstConsecutiveStaticIp.
Linux / Windows node pool
Adding a node pool
* Add (or copy) an entry in the agentPoolProfiles section in the _output/<clustername>/apimodel.json file
Removing a node pool
* Delete the related entry from agentPoolProfiles section in the _output/<clustername>/apimodel.json file
* Drain nodes from inside Kubernetes
* Generate and deploy
* Delete VM's and related resources (disk, NIC, availability set) from Azure portal
Resizing Virtual Machines in a node pool
* Modify the vmSize in the agentPoolProfiles section
* Generate and deploy
Resizing a Node Pool
* Should use acs-engine scale see in a few slides the implementation
___
<!-- .slide: id="golang-acs-engine-gen" data-transition="concave" -->
# ACS Engine
* Generate ARM templates from Cluster Definition
* Execute the newly generated ARM templates
* Scale an agent pool inside cluster
* Delete the entire cluster
Note:
## Create Cluster
Deployment of the cluster is relatively straight forward and can be executed again once changes are made to the api model and then regenerated.
* Execute the generated artifacts
* Always use **azuredeploy.json** file
* Check the activity log for status
* Consider leveraging Azure Key Vault for Certs
```sh
az group deployment create --name "acs-default" \
--resource-group "acs-default" \
--template-file "./_output/k8s-acs-default/azuredeploy.json" \
--parameters "./_output/k8s-acs-default/azuredeploy.parameters.json"
```
## Scale Cluster
After a cluster has been deployed using acs engine the cluster can be interacted further by using the scale command.
The scale command can add more nodes to an existing node pool or remove them.
Nodes will always be added or removed from the end of the agent pool. Nodes will be cordoned and drained before deletion.
```sh
acs-engine scale --subscription-id <subscription-id> \
--resource-group acs-default \
--location eastus \
--deployment-dir _output/k8s-acs-default \
--new-node-count 3 \
--node-pool linuxpool1 \
--master-FQDN <fqdn>
```
___
<!-- .slide: id="golang-acs-engine-demo" data-transition="concave" -->
## ACS Engine
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/VuPmL25_Cls" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
Note:
> Demo: Lets quickly look at how acs-engine is leveraged for deploying clusters
___
<!-- .slide: id="golang-ark" data-transition="concave" -->
# ARK
* Manages disaster recovery
* Backups of cluster and restore
* Copy cluster resources across clouds
* Replicate your production environments
Note:
Heptio Ark is a utility for managing disaster recovery, specifically for your Kubernetes cluster resources and persistent volumes.
Ark gives you tools to back up and restore your Kubernetes cluster resources and persistent volumes. Ark lets you:
* Take backups of your cluster and restore in case of loss.
* Copy cluster resources across cloud providers. NOTE: Cloud volume migrations are not yet supported.
* Replicate your production environment for development and testing environments.
Ark consists of:
* A server that runs on your cluster
* A command-line client that runs locally
```sh
ark backup create jenkins --selector app=jenkins-jenkins \
--snapshot-volumes
```
```sh
ark backup create cluster --exclude-namespaces=kube-system \
--snapshot-volumes
```
```sh
ark schedule create gitlab --selector app=gitlab-gitlab \
--snapshot-volumes \
--schedule "0 7 * * *"
```
___
<!-- .slide: id="golang-ark-demo" data-transition="concave" -->
## ARK
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/sHLRedoRSp0" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
Note:
> Demo: ARK can help you with management of disaster recovery
___
<!-- .slide: id="golang-grafana" data-transition="concave" -->
# Grafana / Prometheus
<div class="col-xs-12 col-sm-12 col-md-12">
<ul class="list-unstyled">
<iframe src="https://grafana.k8s.cloud.statcan.ca/d-solo/a72yEIoik/k8s?orgId=1&panelId=13&from=1537965871160&to=1537976671160&var-node=172.20.57.4" width="900" height="250" frameborder="0"></iframe>
</ul>
</div>
<div class="col-xs-12 col-sm-12 col-md-12">
<ul class="list-unstyled">
<iframe src="https://grafana.k8s.cloud.statcan.ca/d-solo/a72yEIoik/k8s?orgId=1&from=1537803639069&to=1537976439069&panelId=14&var-node=172.20.57.4" width="900" height="250" frameborder="0"></iframe>
</ul>
</div>
Note:
> Demo: [grafana.k8s.cloud.statcan.ca](http://grafana.k8s.cloud.statcan.ca)
As a time series database, prometheus is often used in the world of monitoring systems in combination with grafana, which is at the very basic level a visualization tool for time series data.
I will show you an example of what one of our dashboards looks like that monitors one of our Kubernetes clusters.
* Brought up in K8S
* Linked with Active Directory
* Assignment to Different Groups
* Dashboard can become embeddable
* Custom Alerts based on metrics you define (slack)
___
<!-- .slide: id="golang-traefik" data-transition="concave" data-background="#FFFFFF" -->
# Traefik

Note:
Træfik is a modern HTTP reverse proxy and load balancer that makes deploying microservices easy.
Træfik integrates with your existing infrastructure components (Docker, Swarm mode, Kubernetes, Marathon, Consul, Etcd, Rancher, Amazon ECS, etc ...) and configures itself automatically and dynamically.
Imagine that you have deployed a bunch of microservices with the help of an orchestrator (like Swarm or Kubernetes) or a service registry (like etcd or consul). Now you want users to access these microservices, and you need a reverse proxy.
Traditional reverse-proxies require that you configure each route that will connect paths and subdomains to each microservice. In an environment where you add, remove, kill, upgrade, or scale your services many times a day, the task of keeping the routes up to date becomes tedious.
This is when Træfik can help you!
Træfik listens to your service registry/orchestrator API and instantly generates the routes so your microservices are connected to the outside world -- without further intervention from your part.
Some of the features that Traefik provides are:
* Continuously updates its configuration (No restarts!)
* Supports multiple load balancing algorithms
* Provides HTTPS to your microservices by leveraging Let's Encrypt (wildcard certificates support)
* Circuit breakers, retry
* High Availability with cluster mode (beta)
* See the magic through its clean web UI
* Websocket, HTTP/2, GRPC ready
* Provides metrics (Rest, Prometheus, Datadog, Statsd, InfluxDB)
* Keeps access logs (JSON)
* Exposes a Rest API
* Packaged as a single binary file (go) and available as a tiny official docker image
The supported providers for Traefik keep growing but some of them are:
* Docker / Swarm mode
* Kubernetes
* Mesos / Marathon
* Rancher (API, Metadata)
* Azure Service Fabric
* Consul Catalog
* Consul / Etcd / Zookeeper / BoltDB
* Eureka
* Amazon ECS
* Amazon DynamoDB
* File
* Rest
___
<!-- .slide: id="golang-traefik" data-transition="concave" data-background="#FFFFFF" -->
# Traefik
* [traefik.k8s.cloud.statcan.ca](http://traefik.k8s.cloud.statcan.ca)
* [traefik.inno.cloud.statcan.ca](http://traefik.inno.cloud.statcan.ca)
* [traefik.devtest.cloud.statcan.ca](http://traefik.devtest.cloud.statcan.ca)
Note:
> Demo: Lets take a look at a couple of our Traefik environments
We use Traefik extensively for our Kubernetes clusters.
* Lets Encrypt for all of our Ingresses in Management Cluster
* Ability for automatic ingress in GitLab CI Pipelines
* CIDR blocking at the Traefik level for JupyterHub
* Passing of special headers for applications that need them
* Working on end to end encryption for all the backend services
___
<!-- .slide: id="golang-hugo" data-transition="concave" -->
# Hugo
* Static site generator 30,000 stars
* WxT support @ wet-boew/wet-boew-hugo
* Used for documentation sites at STC
* GitLab CI generates / deploys to GitLab Pages
Note:
> Demo: [wet-boew/wet-boew-hugo](http://github.com/wet-boew/wet-boew-hugo)
> Demo: [govcloud/website](http://github.com/govcloud/website)
Also will quickly demo and do a brief tour of the govcloud Hugo site.
* Markdown
* Concept of Content Types
* Fully supports i18n
* Supports shortcodes (gh-starred, img, youtube)
* Incredibly fast
* Tons of other features
___
<!-- .slide: id="golang-vault" data-transition="concave" -->
# Vault

Note:
> SKIP: Due to time constraints I will skip this slide.
Vault: A tool for secrets management, encryption as a service, and privileged access management.
Vault is a tool for securely accessing secrets. A secret is anything that you want to tightly control access to, such as API keys, passwords, certificates, and more. Vault provides a unified interface to any secret, while providing tight access control and recording a detailed audit log.
A modern system requires access to a multitude of secrets: database credentials, API keys for external services, credentials for service-oriented architecture communication, etc. Understanding who is accessing what secrets is already very difficult and platform-specific. Adding on key rolling, secure storage, and detailed audit logs is almost impossible without a custom solution. This is where Vault steps in.
The key features of Vault are:
Secure Secret Storage: Arbitrary key/value secrets can be stored in Vault. Vault encrypts these secrets prior to writing them to persistent storage, so gaining access to the raw storage isn't enough to access your secrets. Vault can write to disk, Consul, and more.
Dynamic Secrets: Vault can generate secrets on-demand for some systems, such as AWS or SQL databases. For example, when an application needs to access an S3 bucket, it asks Vault for credentials, and Vault will generate an AWS keypair with valid permissions on demand. After creating these dynamic secrets, Vault will also automatically revoke them after the lease is up.
Data Encryption: Vault can encrypt and decrypt data without storing it. This allows security teams to define encryption parameters and developers to store encrypted data in a location such as SQL without having to design their own encryption methods.
Leasing and Renewal: All secrets in Vault have a lease associated with it. At the end of the lease, Vault will automatically revoke that secret. Clients are able to renew leases via built-in renew APIs.
Revocation: Vault has built-in support for secret revocation. Vault can revoke not only single secrets, but a tree of secrets, for example all secrets read by a specific user, or all secrets of a particular type. Revocation assists in key rolling as well as locking down systems in the case of an intrusion.
* The issuing of short term database credentials
* Root credentials to database
* Vault does checking and then creates the user with right permissions in database
* Full auditing for all actions in Vault
* RESTFul
* Act as a SSL certificate issuer for internal CA purposes (end to end encryption)
* Hashicorp Vault
* Encryption keys never leave a secure environment
* Fine grained ACL right down the secret
* Can do SSH certificates where the SSH server can talk directly to vault
* Use case would be giving a user access only for a period of time
* Can restrict access to operations allowed to do (port forwarding, TTY)
___
<!-- .slide: id="golang-minie" data-transition="concave" -->
# Minie

Note:
This is something I couldn't resist talking about and that is a little go application that we are creating a stats to handle the embargo of data and uploading to the cloud taking into account that data can only be accessed at a certain with an variance of about 3 seconds.
This is where minie comes in and can upload this data with use and with high concurrency!
Additionally as with any good go application you need a good cartoon mascot.
___
<!-- .slide: id="golang-minie-arch" data-transition="concave" -->
# Minie Arch

Note:
So how does this work?
Well first you have your "pre-release" data in lets say a SSC controlled data center.
You then want to securely upload your data into a private / secured storage blob / file container in the cloud.
Minie can handle gb's of data with ease and with high concurrency use all of the available pipe that is given to you, minie copies requests, thousands in parallel and then at a certain time "commits" them.
The commit happens by all of the files already uploaded to the cloud being manually moved to a public blob / file container which is efficient due to most cloud's storage accounts available bandwith.
Minie will be publicly released soon and we are hoping to add support for many more clouds other then Azure.
Shout out to the some pretty amazing gophers I know are in the room!
---
<!-- .slide: id="cloudnative-landscape" data-background-size="contain" data-background-image="/img/architecture/openfirst/cncf-landscape.png" -->
Note:
> Demo: https://landscape.cncf.io/format=landscape
So don't worry you aren't supposed to see the individual details of this slide only to take away two key points:
* There are a lot of cloud native applications
* There are a distinct set of problem sets (Cloud Native Storage, Network, Secuity and Compliance, Service Mesh, yadda yadda)
___
<!-- .slide: id="cloudnative-infra" data-transition="concave" -->
# Cloud Native
> Cloud native infrastructure is infrastructure that is:
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Hidden behind useful abstractions</li>
<li>Controlled by API's</li>
<li>Managed by software</li>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Purpose is to run application lifecycle</li>
<li>Exposes own API</li>
<li>Move up the stack</li>
</div>
Note:
Cloud native infrastructure is infrastructure that is hidden behind useful abstractions, controlled by APIs, managed by software, and has the purpose of running applications. Running infrastructure with these traits gives rise to a new pattern for managing that infrastructure in a scalable, efficient way.
Abstractions are useful when they successfully hide complexity for their consumer. They can enable more complex uses of the technology, but they also limit how the technology is used. They apply to low-level technology, such as how TCP abstracts IP, or higher levels, such as how VMs abstract physical servers. Abstractions should always allow the consumer to “move up the stack” and not reimplement the lower layers.
Cloud native infrastructure needs to abstract the underlying IaaS offerings to provide its own abstractions. The new layer is responsible for controlling the IaaS below it as well as exposing its own APIs to be controlled by a consumer.
Infrastructure that is managed by software is a key differentiator in the cloud. Software-controlled infrastructure enables infrastructure to scale, and it also plays a role in resiliency, provisioning, and maintainability. The software needs to be aware of the infrastructure’s abstractions and know how to take an abstract resource and implement it in consumable IaaS components accordingly.
So at its most fundamental level a cloud native application is engineered to run on a cloud platform and is designed for:
* Resiliency: Embraces failures instead of trying to prevent them; it takes advantage of the dynamic nature of running on a cloud platform
* Agility: Allows for fast deployments and quick iterations
* Operability: Adds control of application life cycles from inside the application instead of relying on external processes and monitors
* Observability: Provides information to answer questions about application state
___
<!-- .slide: id="cloudnative" data-transition="concave" -->
# Cloud Native
> The following doesn't automatically mean your Cloud Native.
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Infra on public cloud</li>
<li>Apps in containers</li>
<li>Container orchestrator</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Microservices</li>
<li>Infra as Code</li>
<li>Config management</li>
</ul>
</div>
Note:
Cloud native infrastructure is not only running infrastructure on a public cloud. Just because you rent server time from someone else does not make your infrastructure cloud native. The processes to manage IaaS are often no different than running a physical data center, and many companies that have migrated existing infrastructure to the cloud have failed to reap the rewards.
Cloud native is not only about running applications in containers. When Netflix pioneered cloud native infrastructure, almost all its applications were deployed with virtualmachine images, not containers. The way you package your applications does not mean you will have the scalability and benefits of autonomous systems. Even if your applications are automatically built and deployed with a continuous integration and continuous delivery pipeline, it does not mean you are benefiting from infrastructure that can complement API-driven deployments.
It also doesn’t mean you only run a container orchestrator (e.g., Kubernetes and Mesos). Container orchestrators provide many platform features needed in cloud native infrastructure, but not using the features as intended means your applications aren't dynamically scheduled to run on a set of servers. This is a very good first step, but there is still work to be done.
Cloud native is not about microservices or infrastructure as code. Microservices enable faster development cycles on smaller distinct functions, but monolithic applications can have the same features that enable them to be managed effectively by software and can also benefit from cloud native infrastructure. Infrastructure as code defines and automates your infrastructure in machine-parsible language or domain-specific language (DSL). Traditional tools to apply code to infrastructure include configuration management tools (e.g., Chef and Puppet). These tools help greatly in automating tasks and providing consistency, but they fall short in providing the necessary abstractions to describe infrastructure beyond a single server. Configuration management tools automate one server at a time and depend on humans to tie together the functionality provided by the servers. This positions humans as a potential bottleneck for infrastructure scale. These tools also don’t automate the extra parts of cloud infrastructure (e.g., storage and network that are needed to make a complete system.
___
<!-- .slide: id="cloudnative-impl" data-transition="concave" -->
# Traits
> Acquire the traits of Resiliency, Agility, Operability, Observability through:
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Microservices</li>
<li>Health reporting</li>
<li>Telemetry data</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Resiliency</li>
<li>Declarative not Reactive</li>
</ul>
</div>
Note:
Cloud native applications acquire the traits of (Resiliency, Agility, Operability, Observability) through various methods.
The following represents a common way to implement the desired characteristics:
> Reminder: It can often depend on where your applications run and the processes and culture of the business.
* Microservices: Separate clearly defined functionality into smaller services and let each service independently iterate
* Health reporting: To increase the operability of cloud native applications, applications should expose a health check, liveness, and readyness probes
* Telemetry data: Teleetry data can overlap with health reporting, but serve different purposes. Health reporting informs us of application life cycle, while telemetry data informs us of application business objectives.
* How many requests per minute does the application receive?
* Are there any errors?
* What is the application latency?
* How long does it take to place an order?
* Resiliency: Become resilient to failure and embrace it as a function of design.
* Declarative: Communication through the network through REST and/or Remote Procedure Calls (RPC)
ToDo:
* Mention about Hybrid Cloud and On-Premise which is likely a big deal for Stats Can.
* Just mention all public clouds
___
<!-- .slide: id="cloudnative-cncf" data-transition="concave" -->
# Cloud Native: CNCF
> Orchestration of containers as part of a microservices architecture.
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Containerization</li>
<li>Dynamically orchestrated</li>
<li>Microservices oriented</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Optimized resource utilization</li>
<li>Distributed computing</li>
<li>41,145 Contributors</li>
</ul>
</div>
Note:
> Demo: https://www.cncf.io/
The Cloud Native Computing Foundation is an open source software foundation dedicated to making cloud native computing universal and sustainable and something I truly believe the government should be embracing. Not only because it perfectly aligns with our Open First policy on Cloud Computing.
Cloud native computing uses an open source software stack to deploy applications as microservices, packaging each part into its own container, and dynamically orchestrating those containers to optimize resource utilization.
The CNCF serves as the vendor-neutral home for many of the fastest-growing projects on GitHub, including Kubernetes, Prometheus and Envoy, fostering collaboration between the industry’s top developers, end users, and vendors.
___
<!-- .slide: id="cloudnative-cncf-inuse" data-transition="concave" -->
# CNCF: IN USE
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled"><img src="/img/architecture/openfirst/cncf-kubernetes.png" height=200px></img></li>
<li class="list-unstyled"><img src="/img/architecture/openfirst/cncf-prometheus.svg" height=200px></img></li>
</ul>
</div>
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled"><img src="/img/architecture/openfirst/cncf-helm.png" height=200px></img></li>
<li class="list-unstyled"><img src="/img/architecture/openfirst/cncf-cni2.png" height=200px></img></li>
</ul>
</div>
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled"><img src="/img/architecture/openfirst/cncf-grpc2.png" height=200px></img></li>
<li class="list-unstyled"><img src="/img/architecture/openfirst/cncf-rook.png" height=200px></img></li>
</ul>
</div>
Note:
The following cncf projects are some of the ones we use internally at StatsCan.
* Kubernetes: World’s most popular container-orchestration platform and future serverless benefactor
* Prometheus: Delivers real-time monitoring, alerting and time-series database capabilities
* Helm: Helm is a package manager that provides an easy way to find, share, and use software built for Kubernetes
* CNI: Container Networking Interface project was created by a collection of industry organizations in order to standardize the basic network interface for containers
* GRPC: gRPC is a high-performance RPC framework developed by Google and optimized for the large-scale, multi-platform nature of cloud native computing environments
* Rook: File, Block, and Object Storage Services for your Cloud-Native Environments
___
<!-- .slide: id="cloudnative-cncf-meetups" data-transition="concave" -->
# GoC Meetups
* GoC Cloud Native Working Group
* 80+ Members
* CDS / Statistics Canada
* Usually 2 x 45 minute sessions
Note:
At this point I thought I would just quickly mention our monthly Cloud Native Meetups for the GoC
This meetup consists of a group of people interested in improving government digital services through Cloud Native design.
For our purposes Cloud Native design refers to the architectural design, deployment, and operation of applications.
We try to learn and share our experiences of building highly distributed applications via a micro-services approach that can scale on demand.
This is facilitated through the use of Containers (Docker) which helps you build, ship and run applications anytime and anywhere. Containers ensures agility, portability and control for all your distributed apps.
Additionally we will discuss how to orchestrate Containers via Kubernetes which has become the standard for scheduling and orchestrating containers at scale with an immense community behind it.
Any skill level is welcome and every month encourage people to submit their own demos and host the meetup!
> Demo: http://govcloud.ca
> Meetup: https://www.meetup.com/goc-cloud-native/
> Youtube: https://www.youtube.com/channel/UC00nN9hhb4q6IChP8yEIzGA/playlists
> Video: Example of video we upload gRPC
___
<!-- .slide: id="cloudnative-cncf-meetups-past" data-transition="concave" -->
# GoC Past Meetups
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Container Architecture</li>
<li>Kubernetes Orchestrator</li>
<li>Azure ACS/AKS and ACS-Engine</li>
<li>Terraform</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>JupyterHub</li>
<li>gRPC/Protobuffers</li>
<li>Artifactory / XRay</li>
</ul>
</div>
Note:
If you are interested here is a list of some of the past sessions we have had at our meetups.
___
<!-- .slide: id="cloudnative-cncf-meetups-future" data-transition="concave" -->
# GoC Future Meetups
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>GCTools</li>
<li>OpenShift</li>
<li>Traefik</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Windows Containers</li>
<li>Rancher Cattle</li>
<li>Terraform with GitLab CI</li>
</ul>
</div>
Note:
The following represents a list of future upcoming presentations we are hoping to have:
* GCTools is willing to do a demo and show off their CI/CD process
* OpenShift demo by both CDS and RedHat
* Traefik presentation given by one of the maintainers who met a K8S meetup
* Terraform with GitLab CI by Andriy Drozdyuk
* Bernard Maltais (PSPC) showcasing Rancher Cattle
* Mark Tessier / William Hearn discussing Windows containers
* CNCF / Kube Hunter presentation by Aqua
---
<!-- .slide: id="containers-docker-nyan" data-background-size="contain" data-background="/img/architecture/openfirst/nyan_docker.gif" -->
___
<!-- .slide: id="containers-overview" data-transition="concave" -->
# Containerization
> Agile, lightweight building blocks to build, ship, and run any application, across any infrastructure
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Platform independence</li>
<li>Resource efficiency and density</li>
<li>Effective isolation and resource sharing</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Immense and smooth scaling</li>
<li>Operational simplicity</li>
<li>Developer productivity</li>
<li>Speed</li>
</ul>
</div>
Note:
> Demo: https://www.cncf.io/blog/2018/08/29/cncf-survey-use-of-cloud-native-technologies-in-production-has-grown-over-200-percent/
Everyone that learns about containers and their server immutability concept invariably loves them, because of the power they give, both on the development and in the deployment sides.
**Platform independence: Build it once, run it anywhere**
A major benefit of containers is their portability. In particular containers help to facilitate a cloud native approach via a microservices architectural design pattern.
A container wraps up an application with everything it needs to run, like configuration files and dependencies. This enables you to easily and reliably run applications on different environments such as your local desktop, physical servers virtual servers, testing, staging, production environments and public or private clouds.
This portability grants organisations a great amount of flexibility, speeds up the development process and makes it easier to switch to another cloud environment or provider, if need be.
**Resource efficiency and density**
Since containers do not require a separate operating system, they use up less resources. While a VM often measures several gigabytes in size, a container usually measures only a few dozen megabytes, making it possible to run many more containers than VMs on a single server.
Since containers have a higher utilisation level with regard to the underlying hardware, you require less hardware, resulting in a reduction of bare metal costs as well as datacentre costs.
**Effective isolation and resource sharing**
Although containers run on the same server and use the same resources, they do not interact with each other. If one application crashes, other containers with the same application will keep running flawlessly and won’t experience any technical problems. This isolation also decreases security risks: If one application should be hacked or breached by malware, any resulting negative effects won’t spread to the other running containers.
**Speed: Start, create, replicate or destroy containers in seconds**
As mentioned before, containers are lightweight and start in less than a second since they do not require an operating system boot. Creating, replicating or destroying containers is also just a matter of seconds, thus greatly speeding up the development process, the time to market and the operational speed. Releasing new software or versions has never been so easy and quick. But the increased speed also offers great opportunities for improving customer experience, since it enables organisations and developers to act quickly, for example when it comes to fixing bugs or adding new features.
**Immense and smooth scaling**
A major benefit of containers is that they offer the possibility of horizontal scaling, meaning you add more identical containers within a cluster to scale out. With smart scaling, where you only run the containers needed in real time, you can reduce your resource costs drastically and accelerate your return on investment. Container technology and horizontal scaling has been used by major vendors like Google and Twitter for years now.
**Operational simplicity**
Contrary to traditional virtualisation, where each VM has its own OS, containers execute application processes in isolation from the underlying host OS. This means that your host OS doesn’t need specific software to run applications, which makes it simpler to manage your host system and quickly apply updates and security patches.
**Improved developer productivity and development pipeline**
A container-based infrastructure offers many advantages, promoting an effective development pipeline. Let’s start with one of the most well-known benefits. As mentioned before, containers ensure that applications run and work as designed locally. This elimination of environmental inconsistencies makes testing and debugging less complicated and less time-consuming since there are fewer differences between running your application on your workstation, test server or in production environment. The same goes for updating your applications: you simply modify the configuration file, create new containers and destroy the old ones, a process which can be executed in seconds. In addition to these well-known benefits, container tools like Docker offer many other advantages. One of these is version control, making it possible for you to roll-out or roll-back with zero downtime. The possibility to use a remote repository is also a major benefit when working in a project-team, since it enables you to share your container with others.
## Data Points
* 71% of Fortune 100 companies are running containers
___
<!-- .slide: id="containers-docker" data-transition="concave" -->
# Docker
* Docker for Mac
* Docker for Windows
* Helpful Tips
Note:
> Demo: Docker for Mac
___
<!-- .slide: id="containers-vscode" data-transition="concave" -->
# VSCode
* Dockerfile code completion
* Docker Compose support
* Generation of Docker files
* Docker Hub
* Linting
Note:
> Demo: Some Dockerfiles in VSCode
___
<!-- .slide: id="windows" data-transition="concave" data-background="#FFFFFF" -->
# Windows

Note:
> Demo: https://www.microsoft.com/en-ca/cloud-platform/containers
> Whitepaper: http://download.microsoft.com/download/7/6/8/768E8E11-1C4B-4C5C-9211-96918C324722/Containerized%20Docker%20Application%20Lifecycle%20with%20Microsoft%20Platform%20and%20Tools%20(eBook).pdf
Microsoft is doing a lot of great things in the Container space and honestly this is coming from a Linux developer.
* VSCode works on Windows
* Visual Studio
* Integrated Docker tooling and full application lifecycle
* Multi-container Support via Docker-Compose
* Support orchestrators like Kubernetes
* Porting MSSQL Server to Linux
___
<!-- .slide: id="windows-server" data-transition="concave" data-background="#FFFFFF" -->
# Windows Server
> Windows Server Containers native to Windows Server 2016
Docker enables full ecosystem of tools:
* PowerShell
* CLI
* Docker Data Center
* Hyper-V Isolation
* **New**: Active Directory (MSI)
Note:
___
<!-- .slide: id="windows-server-startup" data-transition="concave" data-background="#FFFFFF" -->
# Windows Server
> Compare the startup time performance of NodeJS
| Nano Server | | Windows Server Core |
| ------------- | ----------------------- | -------------------- |
| < 600 ms | Windows Server Conainer | 1s |
| 1.75s | Hyper-V Isolation | 3.3s |
| 3 s | Virtual Machine | 5-60+ |
Note:
___
<!-- .slide: id="windows-server-dockerfile" data-transition="concave" data-background="#FFFFFF" -->
# Windows Dockerfile
> Demo: Lets take a look at a valid Dockerfile
* Artifactory
* Nuget
* .Net Build / MSPublish
* Multi-Stage Build
Note:
Let's take a look at the following Dockerfile.
## Build Container
Essentially we are running an official image used for running .NET Framework applications on Windows Server Core
* Pull from microsoft/dotnet-framework using the 4.7.2-sdk-windowsservercore-1803 tag and giving the `FROM` a `build` name declaration
* We are doing something interesting in that we prefix our artifactory instance's docker repo as a proxy through
* Note the 1803 tag as opposed to 1709 in the next slide I will tag about this important detail more
* We then switch to the `/app` directory conveniently placed by the base image
* We now can copy all of our current directory into the container (excluding .dockerignore)
* The first step should be to always restore from Nuget your dependant libraries (Artifactory)
* The next step is to then run `dotnet msbuild` passing in your respective configuration parameters
## Multi Stage Build
What you might notice now is that we are now calling a completely different container which is used for hosting WCF services in Windows Server Core
* Pull from microsoft/wcf using the 4.7.2-sdk-windowsservercore-1803 tag and giving the `FROM` a `runtime` name declaration
* We then just make ourselves a new directory and set it as our default
* Now for the fun step of calling what we build in our earlier build container and just copying the newly built artifact itself into the new container
* Finally we leverage powershell to quickly launch us a new IIS Site name SecurityService
---
<!-- .slide: id="k8s-magic" data-background-size="contain" data-background="https://media.giphy.com/media/12NUbkX6p4xOO4/giphy.gif" -->
___
<!-- .slide: id="k8s" data-transition="concave" -->
# Kubernetes
> Kubernetes is the world’s most popular container-orchestration platform and the first CNCF project.
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Managed complexity</li>
<li>Open Service Broker</li>
<li>Multi cloud</li>
<li>Self-healing</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Google backed</li>
<li>Vibrant community</li>
<li>Big name supporters</li>
<li>No vendor lock-in</li>
</ul>
</div>
Note:
Kubernetes helps users build, scale and manage modern applications and their dynamic lifecycles.
First developed at Google, Kubernetes now counts 5000+ contributors and is used by some of the world’s most-innovative companies, across a wide range of industries.
The cluster scheduler capability lets developers build cloud native applications while focusing on code rather than ops.
Kubernetes future-proofs application development and infrastructure management on-premises or in the cloud, without vendor or cloud-provider lock-in.
## Background
A container orchestrator is a software that is able to orchestrate and organize containers across any number of physical or virtual nodes. The potential of this is enormous, as it greatly simplifies the deployment of the infrastructure (each node only has Docker installed) and its operation (as all servers are exactly equal). The container orchestrator takes in account things as failing nodes, adding more nodes to the cluster or removing nodes from the cluster by moving the containers from one node to another to keep them available at all times.
While containers + orchestrators technology not only resolves a lot of problems related with infrastructure management, it also resolves a lot of problems regarding deploying software in the infrastructure, as the software, its dependencies and runtime are always deployed at the same time, minimizing the errors commonly associated to deployments in non-immutable environments.
Kubernetes has won the orchestrator wars, hands down and as of 2018 now takes center stage. This is proved by every single cloud vendor integrating with it and providing their own managed service. Additionally by most PAAS's offering first class support for it. (Pivotal, OpenShift, Tectonic)
**Managed complexity**: Automation of the deployment, scaling, and operation of application containers in a clustered environment via primitives
**Vendor Lock-in**: Essentially every major cloud provider (public, private, hybrid) support Kubernetes
**Multi-Cloud**: Ideal for managing multi-cloud environments / workloads
**Self-healing**: Auto-placement, auto-restart, auto-replication, auto-scaling
**Google Backed**: Originally built by Google leveraging a decade of experience running containers at scale
**Vibrant Community**: One of the fastest moving projects in open source history, 2nd largest. Additionally over 30,000 users on slack many google engineers.
**Big Name Supporters**: Google, Microsoft, AWS, IBM, RedHat, Oracle, VMWare, Intel, Pivotal etc
**Flexibility**: Simplicity of a PaaS with the flexibility of IaaS
**Powerful Primitives**:
* Pod
* Service
* Volume
* Namespace
* ReplicaSet
* Deployment
* StatefulSet
* DaemonSet
* Job
> Interesting data points
* 54% of Fortune 100 companies are running Kubernetes
* Housed within a large, neutral open source foundation, the Cloud Native Computing Foundation
* CNCF consists of enterprise companies such as Microsoft, Google, AWS, SAP, Oracle, Pivotal, etc
* Kubernetes has won the orchestration wars and is recognized as the de facto standard for container orchestration
* Gartner: By 2020, more than 50% of global enterprises will be running containerized applications in production.
* With that, Kubernetes has emerged as the leading orchestration method in the market with a 71% adoption rate.
* Second largest repository on GitHub only behind Linux
* More then 2300 contributors
* Used by some of the worlds most innovative companies
* Over 75,000 members on Slack across different SIG's
___
<!-- .slide: id="k8s-gov" data-transition="concave" -->
# Government
> Kubernetes aligns with governments strategic direction
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>SSC Cloud Platform</li>
<li>CSE / CSIS</li>
<li>CDS / TBS</li>
<li>STC</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>OpenShift</li>
<li>Pivotal</li>
<li>IBM</li>
<li>Oracle</li>
</ul>
</div>
Note:
SSC now has its own Cloud Platform (OpenShift). RedHat's corporate offering of Kubernetes
A few other departments have either procured OpenShift / Pivotal:
* CSEC / CSIS: Using OpenShift for a few years
* CDS: Have a year license of OpenShift
* ESDC / ISED: Building apps and onboarding on OpenShift
* TBS: Evaluating between OpenShift / Pivotal
* STC: Evaluating between OpenShift / Pivotal / AKS etc
> Can send full list of Departments as is impressive the agreement on Kubernetes
___
<!-- .slide: id="chart-overview" data-transition="concave" -->
# Charts
Note:
Helm uses a packaging format called charts. A chart is a collection of files that describe a related set of Kubernetes resources. A single chart might be used to deploy something simple, like a memcached pod, or something complex, like a full web app stack with HTTP servers, databases, caches, and so on.
Charts are created as files laid out in a particular directory tree, then they can be packaged into versioned archives to be deployed.
___
<!-- .slide: id="chart-inuse" data-transition="concave" -->
# Charts: In Use
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled">Artifactory/X-Ray</li>
<li class="list-unstyled">Autoscaler</li>
<li class="list-unstyled">Drupal</li>
<li class="list-unstyled">Elasticsearch</li>
<li class="list-unstyled">GitLab</li>
<li class="list-unstyled">GitLab Runner</li>
<li class="list-unstyled">Grafana</li>
<li class="list-unstyled">Hadoop</li>
</ul>
</div>
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled">Jenkins</li>
<li class="list-unstyled">JypyterHub</li>
<li class="list-unstyled">Kylo</li>
<li class="list-unstyled">Minio</li>
<li class="list-unstyled">Nifi</li>
<li class="list-unstyled">Octopus</li>
<li class="list-unstyled">OMR</li>
<li class="list-unstyled">Pachyderm</li>
</ul>
</div>
<div class="col-xs-4 col-sm-4 col-md-4">
<ul class="list-unstyled">
<li class="list-unstyled">Prometheus</li>
<li class="list-unstyled">SAS4C</li>
<li class="list-unstyled">Sentry</li>
<li class="list-unstyled">SonarQube</li>
<li class="list-unstyled">Spark</li>
<li class="list-unstyled">Traefik</li>
<li class="list-unstyled">Zeppelin</li>
<li class="list-unstyled">Zookeeper</li>
</ul>
</div>
Note:
Some of the charts we either created or leverage as Stats Can are given in this slide.
___
<!-- .slide: id="chart-arch" data-transition="concave" -->
# Architecture
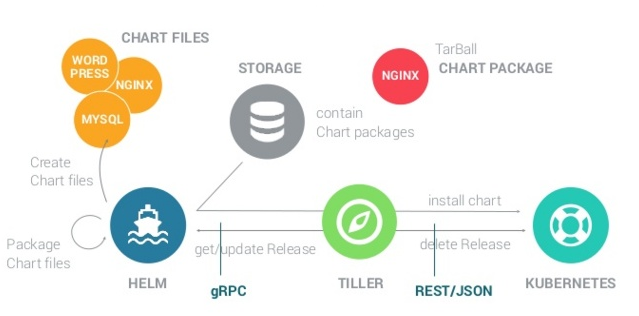
Note:
Tiller removed in Helm 3, and Lua scripting engine will be added.
___
<!-- .slide: id="chart-app-delivery" data-transition="concave" -->
# App Delivery
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/tE3k-pOJdTc" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
Note:
The following illustrates an example of using charts via the optional UI rather then the command line.
___
<!-- .slide: id="chart-gitlab" data-transition="concave" -->
# Jenkins

Note:
We use Jenkins to deploy much of our architecture through a Infrastructure as Code approach.
Jenkins is great because of its:
* Plugin Architecture
* Azure Plugins
* Artifactory
* Ability to build and deploy applications to multiple Kubernetes Clusters
* .NET application running on Linux frontend and VM backend for Databases (90%)
* Moving Jenkins agent pool to Kubernetes cluster
___
<!-- .slide: id="chart-gitlab" data-transition="concave" -->
# GitLab
Note:
We use GitLab to host our source code as well as GitLab CI to perform builds and deployment to Kubernetes.
Of course Jenkins can do this to but we have found the polish and workflow in GitLab to be quite exceptional for K8S.
This is likely because the same people who help to build and steer Kubernetes development also use GitLab itself.
___
<!-- .slide: id="chart-gitlab-overview" data-transition="concave" -->
# GitLab
> Demo: Lets show of the key benefits GitLab provides us
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>GitLab running in K8S</li>
<li>CI runners in separate cluster</li>
<li>Multiple backups via ARK / CronJob</li>
<li>9 months operational</li>
</ul>
</div>
<div class="col-xs-6 col-sm-6 col-md-6">
<ul class="list-unstyled">
<li>Highest in Gartner</li>
<li>Fully cloud native</li>
<li>Improved build/test workflow</li>
</ul>
</div>
Note:
There are a few key important points I would like to talk about in order to show the value GitLab brings to us:
* Running in Kubernetes without issue for 9+ months
* CI runners run in a separate cluster so as to not affect production (demo)
* ARK is leveraged to perform daily PVC backups (demo)
* Updated GitLab over 5 releases without issue simply by bumping container version
* All of our configuration is housed in the Helm chart
* GitLab pages is enabled with some teams using Hugo to generate static site documentation
* Prometheus monitoring is enabled so can see health of GitLab as well as CI builds
* Email is set to use SendGrid
* We have both LDAP and Azure Oauth authentication to reduce accounts
* Full CI/CD pipeline across a few projects
* Drupal @ ADSD
* .NET @ ADSD
* Python / Pachyderm @ ADD
* NodeJS @ Digital Innovation
___
<!-- .slide: id="chart-gitlab-cicd" data-transition="concave" -->
# GitLab CI/CD
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/Nj6dqU7u0CI" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
Note:
The following video which I will have to fast forward to different key points shows a complete CI/CD lifecycle of a Drupal.
Of interest you will notice that we are using a Pull Request which will:
* Get packaged into a Drupal Container
* Launched as part of a series of containers using Helm
* Drupal
* MySQL
* PHP-FPM
* Nginx
* Minio for Stateless which backs file in Azure blob storage
* An ingress will be leveraged using the git sha and branch name for a unique individual environment
___
<!-- .slide: id="chart-jfrog-workflow" data-transition="concave" data-background="#FFFFFF" -->
# jFrog
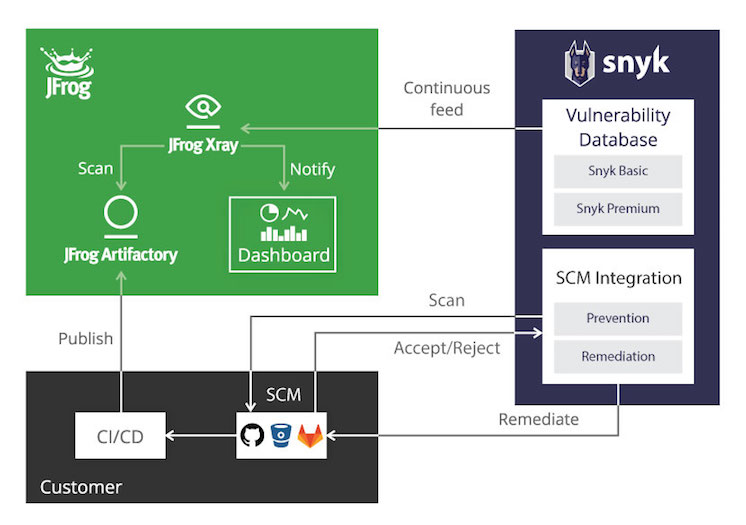
Note:
___
<!-- .slide: id="chart-jfrog" data-transition="concave" data-background="#FFFFFF" -->
## jFrog
* Facilitates a DevSecOps pipeline
* Artifactory for package management
* XRay for package analysis
* Complete visibility of your dependencies
Note:
At the time of this writing there is no universal open source package management system that met our needs.
As a result we procured jFrog Artifactory and XRay to support our open source work and the larger toolchain at Statistics Canada.
___
<!-- .slide: id="chart-artifactory" data-transition="concave" data-background="#FFFFFF" -->
## Artifactory
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/CypEkbB-JRU" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
Note:
> Demo: https://www.youtube.com/watch?v=r2_A5CPo43U
As a universal repository manager, Artifactory integrates with your existing ecosystem supporting end-to-end binary management that overcomes the complexity of working with different software package management systems, and provides consistency to your CI/CD workflow.
At Statistics Canada we are trying to ensure that all of our packages are proxied through Artifactory.
* R
* CRAN
* C++ / C# / .NET
* Python
* PHP
* NodeJS
* containers
___
<!-- .slide: id="chart-xray" data-transition="concave" data-background="#FFFFFF" -->
## X-Ray
<div class="stretch">
<iframe height="100%" width="100%" src="https://www.youtube.com/embed/lghfzM9R1i0" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
</div>
Note:
XRay scans for all software packages in artifactory and then will provide multilayer analysis of your containers and
software artifacts for all sorts of vulnerabilities, license compliance and quality assurance.
In terms of vulnerabilities XRay will scan all of your artifacts against all known CVE's to see if there is a security risk. But what I find most need is how XRay can perform deep recursive scans of Docker container down to each individual layer.
With Artifactory + XRay you can continuously govern and audit all artifacts consumed and produced in your CI/CD pipeline.
___
<!-- .slide: id="chart-jfrog-octopus" data-transition="concave" data-background="#FFFFFF" -->
# Octopus

Note:
Octopus takes over where your Continuous Integration server ends, enabling you to easily automate even the most complicated application deployments, whether on-premises or in the cloud.
___
<!-- .slide: id="chart-jfrog-octopus-overview" data-transition="concave" data-background="#FFFFFF" -->
# Octopus
* Chart built by Statistics Canada
* Will be taken upstream by official project
* Leverages both Linux + Windows Nodes
* Recently added Kubernetes + Helm support
Note:
> Demo: https://github.com/helm/charts/pull/7769
___
<!-- .slide: id="chart-omr data-transition="concave" data-background="#FFFFFF" -->
# OMR
* Chart built by Statistics Canada
* Leverages both Linux + Windows Nodes
* .NET deployment 13 different components
* Largely web services in Kubernetes
* Database back-end still in IaaS
Note:
> Demo: Deploying the OMR chart and show what happens
---
<!-- .slide: id="serverless-challenger" data-background-size="contain" data-background="https://media.giphy.com/media/bGd3K98aIx104/giphy.gif" -->
___
<!-- .slide: id="serverless" data-transition="concave" -->
# Serverless
* Right tool for the right job
* Pros and Cons
* FaaS
* Use Cases
Note:
I want to tell you about the pros and cons of managing your own containers versus letting serverless do it for you.
Hopefully I won't add to the tribal warfare so will try to get everyone to agree on a couple of facts as both technologies have awesome use-cases and valid pain points. Though I do want to point that most serverless platforms are themselves running as containers you just don't need to care about that detail.
There are several factors to take into account:
* Development speed / Time to Market
* Complex Deployment Scenarios
* Time it takes to deploy your application
* Vendor lock-in (many people quibble over this one)
* Cost
# Containers
Containers themselves won't give you auto-scaling by default it's is something you need to set up yourself. Luckily we use Kubernetes which makes this incredibly easy thanks to the Horizontal Pod Autoscaler which automatically scales the number of pods in a replication controller, deployment or replica set based on observed CPU utilization (or, with custom metrics support, on some other application-provided metrics).
## Pros
* Full control of resources
* More freedom and control
* Much more monitoring and debugging tools at your disposal as ecosystem is way more evolved
* With containers your team with have same development environment no matter OS they using
* Makes it incredibly easy for larger teams to be efficient
## Cons
* Complexity introduces as need to learn the ecosystem and various tools at your disposal
* Complexity means more moving parts which can introduce more cost
* Paying for the resources all the time no matter if have traffic or not
## Use Cases
The use-cases for containerized applications are significantly wider than with serverless.
* Refactor existing monolithic applications to container-based setups.
* To get maximum benefit, you should split up your monolithic application into individual microservices.
Among the usual application you'll use containers for are:
* Web APIs
* Machine learning computations
* long-running processes.
In short, whatever you already use traditional servers for would be a great candidate to be put into a container. When you're already paying for the servers no matter the load, make sure to really densely pack those virtual machines.
# Serverless
Serverless is often assumed to be Function as a Service (FaaS). That's not entirely true. Serverless is so much more. It should be viewed as an event based system for running code. Meaning, you use various services to create business logic without caring about any servers. You're abstracting away the infrastructure altogether. I should mention that some people refuse to call it serverless and rather just a managed server that you don't deal with but I won't wade too far into that.
Perfect examples can be:
* Hosting static websites on S3
* Using serverless databases like DynamoDB or Aurora Serverless
* Running code without managing servers with Lambda.
Serverless is great if you have sudden traffic spikes which need to be detected and handled instantly.
# Pros
* Don't have to manage any infrastructure
* No operating system updates, no security patches because provider handles it
* Auto-scaling enabled by default with no configuration
* Application shuts down if there's no traffic
* Deployment simplicity, deploy application code to provider and will handle the rest
# Cons
* Magic comes with a price as easy of adding observability to your app with K8S does not apply to serverless
* Only a few viable 3rd part solutions like Dashbird, IOPipe or Datadog
* Have to live with defined limits for processing power and memory
* Pushes you to write more efficient code because of the risk to overload your functions
* If grow too large can cause the dreaded "latency" issue
* FaaS suffers from what are called cold starts where initial invocation of a function may take a second or two for the container to spin up
* Weigh the risk vs reward, is it better to worry less about server but then having less control
* Recover in an error situation
* Beholden to an external entity to fix it
# Use Cases
* Great for microservice architectures whether simple web APIs or task runners
* The ephemeral nature of serverless functions makes them ideal for processing data streams or images.
* You can also use them as Cron jobs where you schedule a function to run at a specific time every day.
* No need to have a server run all the time for a background task that runs every once in a while.
* Keep in mind FaaS is viable only for short-running processes.
* The maximum time an AWS Lambda function can run is 5 minutes.
* If you have some heavy computing tasks, I'd suggest you use a container based setup instead.
___
<!-- .slide: id="kubernetes-serverless" data-transition="concave" -->
# KNative / Istio

* Will be promoted to CNCF soon
* Build, Serving, and Eventing
* Kubernetes Universal Control Plane
Note:
Build
* Pluggable model for building containers from source
* Based on Google's container build service
* Allows develop to define a source for their container, such as a git repo or container registry
Serving
* Automates flow from container to running function
* Scale to Zero, request-driven compute runtime
* Leverages Istio to route traffic amongst revisions
* Routes can send traffic to multiple revisions of the same application
Eventing
* Provides building blocks for consunimg and producing events
* Abstraction for feeds from event sources
* Allows developers to be agnostic to which specific messaging platform is used
* Functions subscribe to and consume events